

Matching patients to suitable clinical trials is a pivotal but highly challenging process in modern medical research. It involves analyzing complex patient medical histories and mapping them against considerable levels of detail found in trial eligibility criteria. These criteria are complex, ambiguous, and heterogeneous, making the undertaking labor-intensive and prone to error, inefficient, and delaying the realization of critical research progress while many patients are kept waiting for experimental treatments. This is exacerbated by the requirement to scale across large collections of trials, especially in areas like oncology and rare diseases, where precision and efficiency are highly valued.
Traditional methods of patient trial matching are twofold: one for cohort-level recruitment is the trial-to-patient match, and the second is the patient-to-trial match with its focus on individual referrals and patient-centric care. Despite this, several limitations plague state-of-the-art neural embedding-based methods. Such shortcomings involve reliance on large-scale annotated datasets that are difficult to obtain, with low computational efficiency and poor capabilities in terms of real-time applications. A lack of transparency regarding the predictions also undermines clinician confidence. One can conclude that such imperfections call for innovative and explainable data-efficient ways to improve matching performance in clinical environments.
To address these challenges, the researchers developed TrialGPT, a groundbreaking framework that leverages large language models (LLMs) to streamline patient-to-trial matching. These three major parts constitute the composition of TrialGPT: TrialGPT-Retrieval, which filters out most irrelevant trials with the help of hybrid fusion retrieval and keywords generated from patient summaries; TrialGPT-Matching, which performs detailed evaluation of the eligibility of patients at criterion level, hence providing natural language explanations and evidence localization; and TrialGPT-Ranking, which aggregates criterion-level results into trial-level scores to prioritize and rule out. This framework integrates deep natural language understanding and generation capabilities, guaranteeing accuracy, explainability, and flexibility for analyzing unstructured medical data.
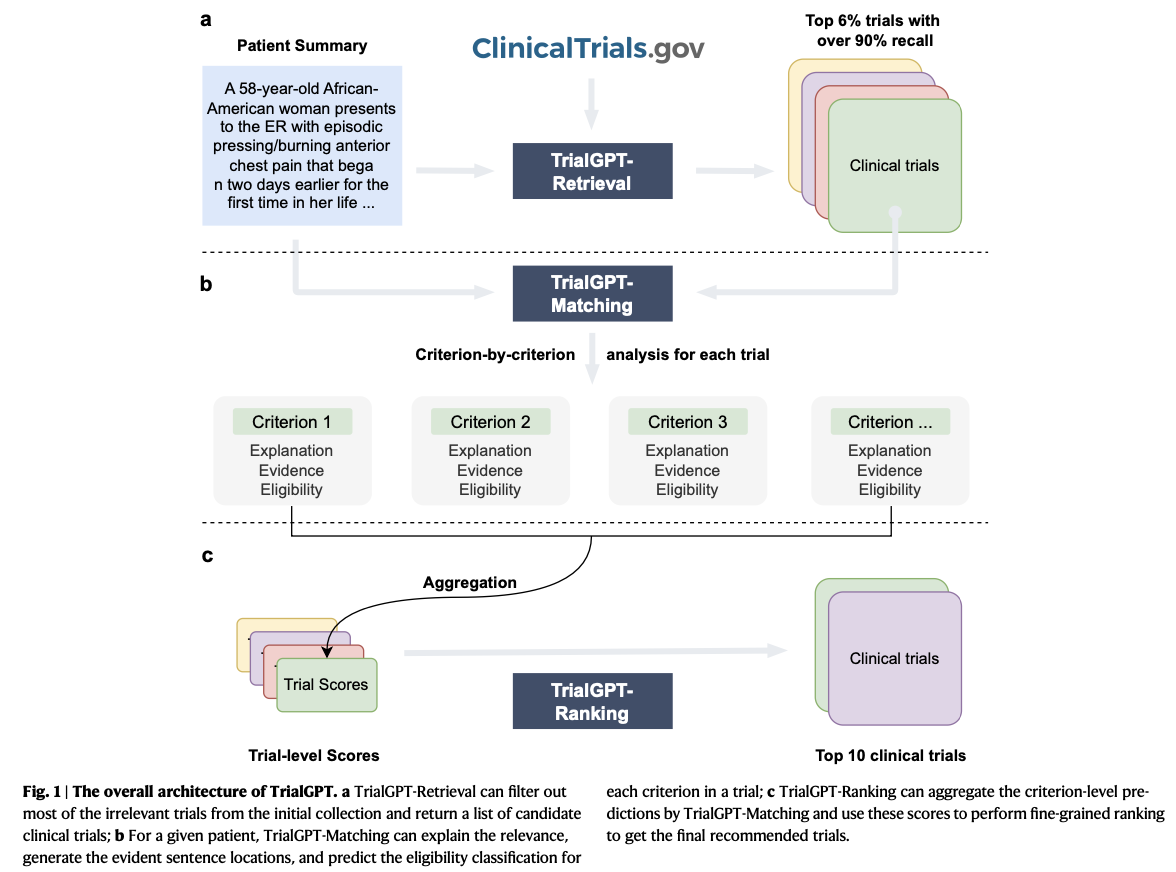
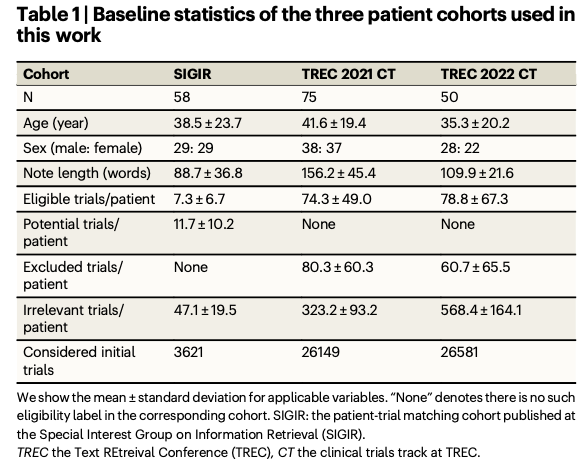
The researchers assessed TrialGPT on three public datasets: SIGIR, TREC 2021, and TREC 2022, covering 183 synthetic patients and over 75,000 trial annotations. The datasets contain a wide range of eligibility criteria categorized into inclusion and exclusion labels. The retrieval component uses GPT-4 to generate context-aware keywords from patient notes with more than 90% recall and reducing the search space by 94%. The matching component conducts a criterion-level analysis which provides high accuracy and is supported by explainable eligibility predictions as well as evidence localization. The ranking approach combines linear and LLM-based aggregation methods efficiently to rank appropriate trials while discarding inappropriate ones, and hence it is well capable of being used at scale in real-world applications.
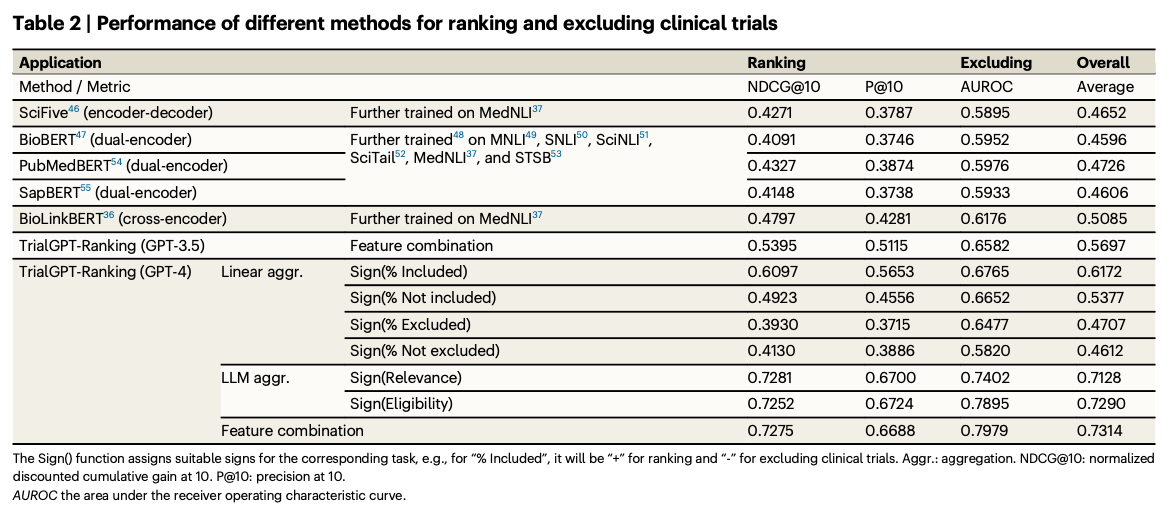
The trialGPT model performed robustly on all relevant benchmarks, solving both retrieval and matching problems. The retrieval module narrowed down large collections of trials while still maintaining good recall for relevant options. The matching module offered criterion-level predictions with accuracy equivalent to human experts in addition to natural language explanations and the evidence at the exact sentence level. Its ranking feature outperformed all other methods in terms of ranking precision and exclusion effectiveness in identifying and ranking eligible trials. Patient-trial matching workflow efficiency was further improved by TrialGPT, leading to a decrease in screening time by over 42%, demonstrating its practical value for clinical trial recruitment.
TrialGPT illustrates a radical solution to the problems of patient-trial matching: scalability, accuracy, and transparency in a novel usage application of LLMs. Its modularity overcomes key limitations in conventional approaches, accelerating patient recruitment processes and streamlining clinical research while producing better patient outcomes. With advanced language understanding integrated with explainable outputs, TrialGPT illustrates a new scale for personalized and efficient trials. Future work may involve the integration of multi-modal data sources and the adaptation of open-source LLMs to various applications for real-world validation.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI VIRTUAL CONFERENCE] SmallCon: Free Virtual GenAI Conference ft. Meta, Mistral, Salesforce, Harvey AI & more. Join us on Dec 11th for this free virtual event to learn what it takes to build big with small models from AI trailblazers like Meta, Mistral AI, Salesforce, Harvey AI, Upstage, Nubank, Nvidia, Hugging Face, and more.
The post This AI Paper Unveils TrialGPT: Revolutionizing Patient-to-Trial Matching with Precision and Speed appeared first on MarkTechPost.



