

Scientific literature synthesis is integral to scientific advancement, allowing researchers to identify trends, refine methods, and make informed decisions. However, with over 45 million scientific papers published annually, staying updated has become a formidable challenge. Limitations hinder synthesizing relevant data from this growing corpus in existing tools, which often need more accuracy, contextual relevance, and comprehensive citation tracking. The complexity of multi-paper synthesis exacerbates the need for specialized systems to manage this vast landscape effectively.
General-purpose language models frequently generate hallucinated citations, with inaccuracies as high as 78–98%, especially in biomedical fields. One of the significant problems researchers face is the lack of reliable tools that provide accurate, contextually appropriate synthesis of scientific literature. Existing tools are often restricted to narrow datasets or single-domain applications, rendering them inadequate for interdisciplinary research. These shortcomings result in inefficient synthesis and unreliable references, creating bottlenecks for biomedicine, computer science, and physics researchers, where accuracy and depth are critical.
Existing methodologies for scientific literature synthesis involve retrieval-augmented language models, which attempt to combine external knowledge sources during inference. However, their reliance on small, proprietary datasets or black-box APIs often limits these models. Tools like PaperQA2 and general-purpose models like GPT-4 could improve citation accuracy and synthesis coherence. Evaluations of such tools typically need more reproducibility or are confined to specific disciplines, further limiting their utility in addressing broader research questions.
Researchers from the University of Washington, Allen Institute for AI, University of Illinois Urbana-Champaign, Carnegie Mellon University, Meta, University of North Carolina Chapel Hill, and Stanford University introduced OpenScholar, a retrieval-augmented language model. OpenScholar integrates a vast datastore of 45 million open-access scientific papers sourced from Semantic Scholar and utilizes advanced retrieval techniques. Its design incorporates a bi-encoder retriever, a cross-encoder reranker, and an iterative self-feedback mechanism, all optimized for scientific literature synthesis. This model stands apart from its competitors by combining domain-specific training, transparent methodologies, and a commitment to open-sourcing its ecosystem.
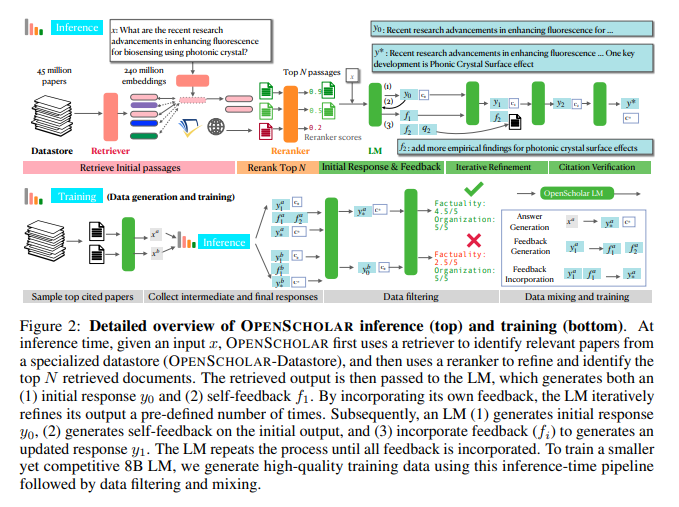
The core methodology behind OpenScholar involves multi-stage processing. First, it retrieves relevant passages from its datastore using a bi-encoder retriever trained on 237 million passage embeddings. A cross-encoder reranker filters these passages to prioritize the most contextually relevant ones. Finally, the language model synthesizes responses, iteratively refining outputs based on generated self-feedback. This iterative process improves accuracy and completeness by incorporating additional information where needed. OpenScholar’s training involved creating high-quality synthetic data from 1 million curated abstracts, generating 130,000 training instances. The final model, OpenScholar-8B, delivers exceptional accuracy and computational efficiency.
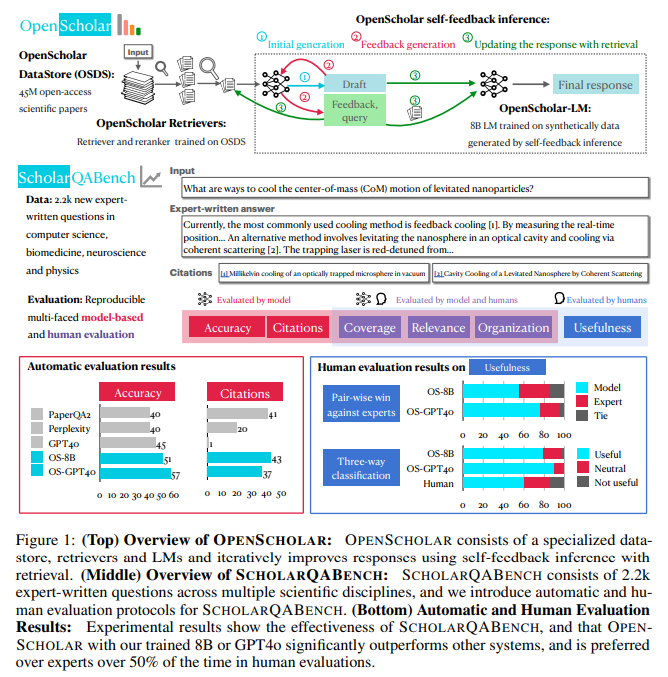
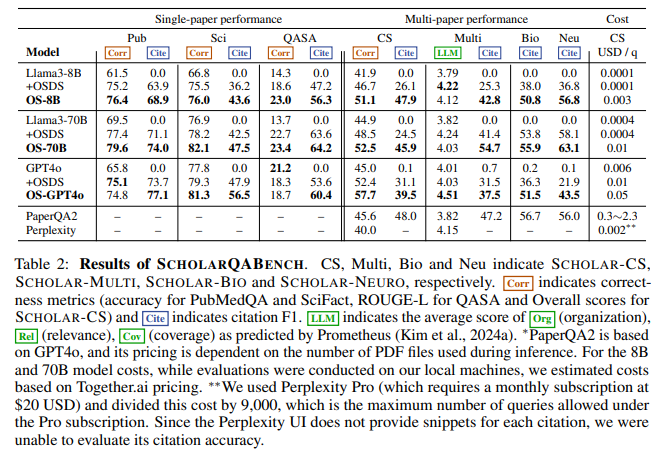
The results of OpenScholar’s performance were validated using the newly developed ScholarQABench benchmark, which spans disciplines such as neuroscience, computer science, and biomedicine. OpenScholar outperformed GPT-4 by 5% and PaperQA2 by 7% in correctness. While GPT-4 hallucinated citations in 78–90% of instances, OpenScholar achieved near-expert citation accuracy, earning a Citation F1 score of 81%. Human evaluators rated OpenScholar’s responses as superior to expert-written ones 51% of the time. OpenScholar improved GPT-4’s correctness by 12% when combined with its retrieval pipeline, showcasing its capacity to enhance even high-performing models. Also, OpenScholar demonstrated significant cost efficiency, with retrieval-based pipelines reducing computation costs by up to 50%.
The key takeaways from OpenScholar’s research and development are:
- Data Utilization: OpenScholar integrates a datastore containing 45 million scientific papers and 237 million passage embeddings, making it the largest open-access corpus for scientific literature synthesis.
- Citation Accuracy: The model achieved a Citation F1 score of 81%, significantly reducing hallucinated citations compared to general-purpose models.
- Efficiency: By leveraging an 8B parameter model and retrieval-augmented processes, OpenScholar balances computational efficiency and performance.
- Expert Preference: Human evaluations preferred OpenScholar-generated responses 51% of the time over expert-written answers.
- Interdisciplinary Utility: OpenScholar performs robustly across domains, including physics, neuroscience, and biomedicine, with high correctness and citation precision.
- Open Ecosystem: Researchers open-sourced all components, including training datasets, evaluation tools, and benchmarks, promoting reproducibility and transparency.

In conclusion, OpenScholar exemplifies a breakthrough in scientific literature synthesis by addressing the limitations of existing tools with a robust, retrieval-augmented model that excels in accuracy, efficiency, and interdisciplinary applicability. With its ability to refine outputs iteratively and ensure citation reliability, OpenScholar provides researchers with a tool to navigate the complexities of modern scientific inquiry. This innovation marks a significant step in enabling researchers to derive actionable insights from an ever-expanding body of scientific knowledge.
Check out the paper, model on Hugging Face, Other details, and code repository on GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI VIRTUAL CONFERENCE] SmallCon: Free Virtual GenAI Conference ft. Meta, Mistral, Salesforce, Harvey AI & more. Join us on Dec 11th for this free virtual event to learn what it takes to build big with small models from AI trailblazers like Meta, Mistral AI, Salesforce, Harvey AI, Upstage, Nubank, Nvidia, Hugging Face, and more.
The post The Allen Institute for AI (AI2) Introduces OpenScholar: An Open Ecosystem for Literature Synthesis Featuring Advanced Datastores and Expert-Level Results appeared first on MarkTechPost.



