

Large Language Models (LLMs) have significantly advanced due to the Transformer architecture, with recent models like Gemini-Pro1.5, Claude-3, GPT4, and Llama3.1 demonstrating capabilities to process hundreds of thousands of tokens. However, these expanded context lengths introduce critical challenges for practical deployment. As sequence length increases, decoding latency escalates and memory constraints become severe bottlenecks. The KV Cache, which stores contextual information in GPU memory during inference, grows proportionally with context length, leading to memory saturation. This fundamental limitation impedes efficient inference processes when handling extensive input sequences, creating a pressing need for optimisation solutions.
While training-free methods exist, they frequently depend on access to attention weights to determine Key-Value pair importance, creating incompatibility with efficient attention algorithms like FlashAttention. These methods often necessitate partial recomputation of attention matrices, introducing both time and memory overhead. Consequently, existing compression algorithms primarily serve to compress prompts before answer generation rather than optimizing memory-constrained generation processes. This fundamental limitation highlights the need for compression techniques that maintain model performance without requiring architectural modifications or compromising compatibility with established efficiency algorithms.
This paper from Sorbonne Université, Inria France, Sapienza University of Rome, University of Edinburgh and Miniml.AI introduces Q-Filters, a robust training-free KV Cache compression technique that utilizes query-based filtering to optimize memory usage without sacrificing model performance. Q-Filters operates by evaluating the importance of Key-Value pairs based on their relevance to the current query, rather than relying on attention weights. This approach ensures compatibility with efficient attention algorithms like FlashAttention while eliminating the need for retraining or architectural modifications. By dynamically assessing and retaining only the most relevant contextual information, Q-Filters achieves significant memory reduction while maintaining inference quality. The method implements a streamlined compression pipeline that integrates seamlessly with existing LLM deployments, offering a practical solution for memory-constrained environments without compromising the model’s ability to process long-context inputs effectively.
Building upon theoretical insights into query-key geometry, Q-Filters presents a sophisticated approach to KV Cache compression that leverages the intrinsic geometric properties of query and key vectors. The method is founded on two critical observations: the existence of a favored common normalized direction for both query and key distributions, and the unidirectional nature of query-key anisotropy. Through rigorous mathematical formulation, the researchers demonstrate that projecting key vectors along this anisotropic direction provides a reliable estimate of attention logits. This insight leads to a streamlined compression algorithm that involves: (1) gathering query representations through model sampling, (2) computing Singular Value Decomposition (SVD) to extract right-vectors, and (3) obtaining positive Q-Filters for each attention head. During inference, the method strategically discards key-value pairs with the lowest projection values along these filters. For models using Grouped-Query Attention, Q-Filters simply average the filters across grouped query representations. Importantly, this approach requires only a one-time preparation step following model training, with the resulting Q-Filters remaining context-agnostic while exploiting fundamental properties of the latent space.
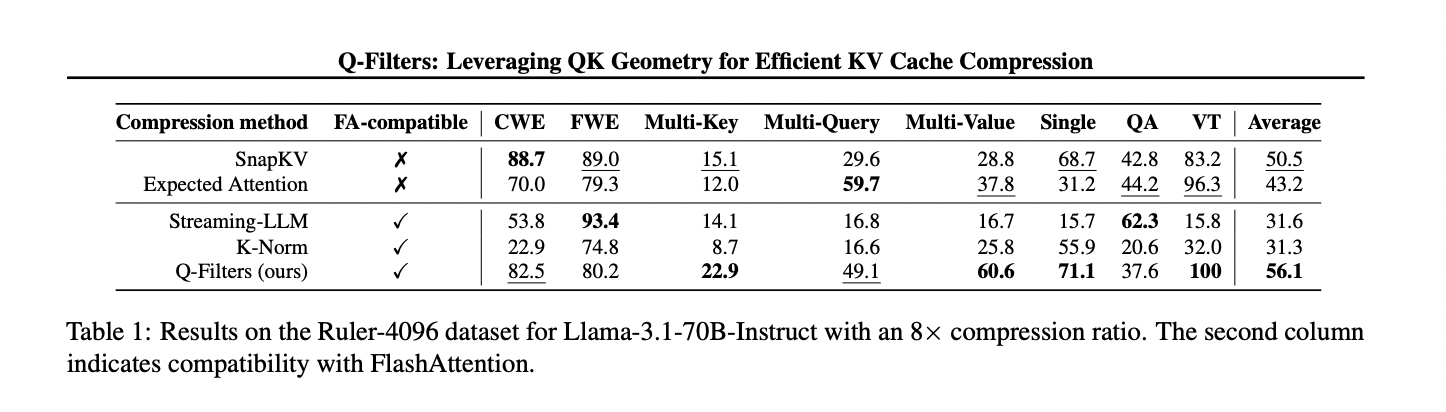
Q-Filters demonstrates exceptional performance across multiple evaluation scenarios, consistently outperforming existing KV Cache compression methods. In language modeling tests on the Pile dataset, the technique achieves the lowest perplexity among all compression schemes, even with maximum KV Cache size restricted to 512 pairs and across extended sequence lengths. This performance advantage scales effectively to larger models, with Llama-3.1-70B showing significant perplexity reduction, particularly in latter portions of sequences where contextual retention becomes critical. In the challenging Needle-in-a-Haystack task, Q-Filters maintains impressive 91% accuracy compared to K-norm’s 63%, successfully preserving crucial information across extreme context lengths from 1K to 64K tokens. Comprehensive evaluation on the Ruler dataset further validates the method’s superiority, particularly at high compression rates (32×), where Q-Filters achieves the highest scores across long context modeling benchmarks. Also, the technique demonstrates remarkable robustness regarding calibration requirements, with diminishing returns beyond 1,000 samples and high vector stability across diverse calibration datasets, confirming its practical efficiency for real-world implementations.
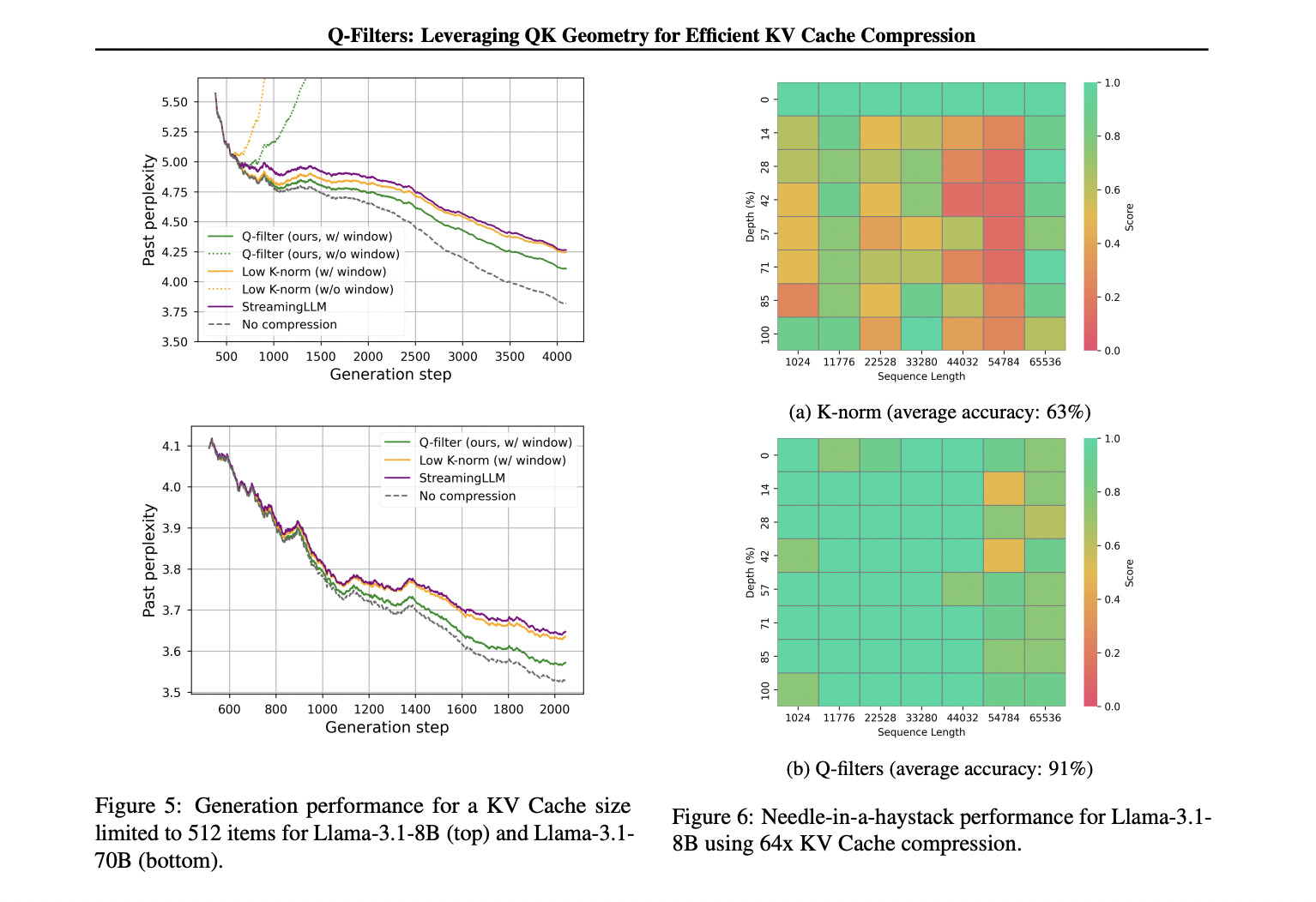
Q-Filters demonstrates exceptional performance across multiple evaluation scenarios, consistently outperforming existing KV Cache compression methods. In language modeling tests on the Pile dataset, the technique achieves the lowest perplexity among all compression schemes, even with maximum KV Cache size restricted to 512 pairs and across extended sequence lengths. This performance advantage scales effectively to larger models, with Llama-3.1-70B showing significant perplexity reduction, particularly in latter portions of sequences where contextual retention becomes critical. In the challenging Needle-in-a-Haystack task, Q-Filters maintains impressive 91% accuracy compared to K-norm’s 63%, successfully preserving crucial information across extreme context lengths from 1K to 64K tokens. Comprehensive evaluation on the Ruler dataset further validates the method’s superiority, particularly at high compression rates (32×), where Q-Filters achieves the highest scores across long context modeling benchmarks. Also, the technique demonstrates remarkable robustness regarding calibration requirements, with diminishing returns beyond 1,000 samples and high vector stability across diverse calibration datasets, confirming its practical efficiency for real-world implementations.
Q-Filters introduces a training-free KV Cache compression method that projects key representations onto query vectors’ main SVD component, accurately approximating attention scores. Compatible with FlashAttention without accessing attention weights, this efficient approach shows superior performance across language modeling, needle-in-a-haystack tests, and Ruler benchmarks for models up to 70B parameters. Q-Filters offers an effective solution for memory-constrained LLM deployments without compromising contextual understanding capabilities.
Check out the Paper and Q-Filters on Hugging Face. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.

The post Q-Filters: A Training-Free AI Method for Efficient KV Cache Compression appeared first on MarkTechPost.



