

Image and video generation has undergone a remarkable transformation, evolving from a seemingly impossible challenge to a task nearly solved by commercial tools like Stable Diffusion and Sora. This progress is largely driven by Multihead Attention (MHA) in transformer architectures, which excel in scaling capabilities. However, this advancement comes with significant computational challenges. The quadratic computational complexity of transformers poses a critical limitation, where increasing image or video resolution exponentially increases processing requirements. For example, doubling an image’s resolution raises computational costs by 16 times, with videos requiring even more. This limitation remains a key obstacle to building high-quality, large-scale generative models for visual content.
Existing approaches to address the computational challenges in generative models include Diffusion models and Fast alternatives to attention. Diffusion models initially used U-Net architectures with attention layers, learning to transform noisy images into natural representations through forward and reverse processes. Alternative strategies focus on reducing attention complexity, including techniques like Reformer, which approximates attention matrices, and Linformer to projects keys and values into lower-dimensional spaces. State-Space Models (SSM) emerged as a promising alternative, offering linear computational complexity. However, these methods have significant limitations, especially in handling spatial variations and maintaining model flexibility across different sequence lengths.
Researchers from LIGM, Ecole Nationale des Ponts et Chauss ´ ees, IP Paris, Univ Gustave Eiffel, CNRS, France ´ and LIX, Ecole Polytechnique, IP Paris, CNRS, France have proposed Polynomial Mixer (PoM), an approach to address the computational challenges in image and video generation. It emerges as an innovative drop-in replacement for MHA, designed to overcome the quadratic complexity limitations of traditional transformer architectures. PoM achieves linear computational complexity for the number of tokens by encoding the entire sequence into an explicit state. PoM maintains the universal sequence-to-sequence approximation capabilities of traditional MHA, positioning it as an alternative for generative modeling.
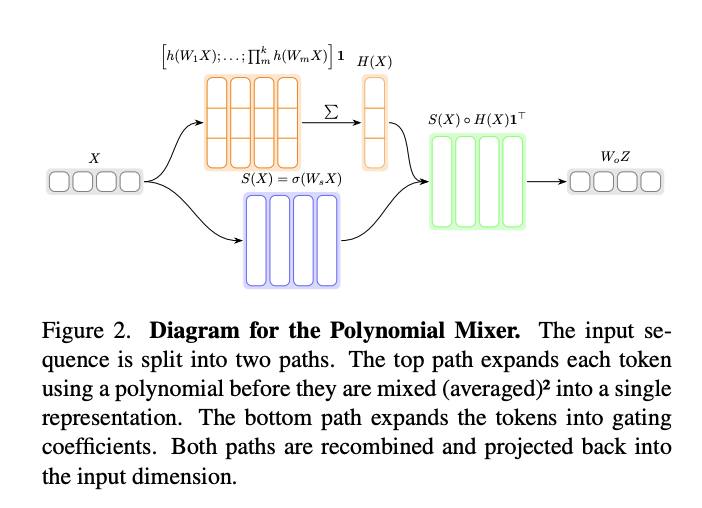
The proposed method PoM features distinct designs for image and video generation. For image generation, the model utilizes a class-conditional Polymorpher similar to the AdaLN variant of DiT. Images are initially encoded through a VAE, with visual tokens enhanced by 2D cosine positional encoding. Class and time step embeddings are integrated through embedding matrices and summed together. Each block includes modulations, a PoM, and feed-forward networks, with PoM often utilizing a second-order polynomial and a two-fold expansion factor. The model incorporates cross-modal PoM operations to aggregate information between text and visual tokens, followed by self-aggregation and feed-forward processing.
Quantitative evaluations reveal promising outcomes for the PoM. The model achieves an FID score of 2.46 using the standard ADM evaluation framework, which is lower than comparable DiT architectures, with the notable caveat that the model was trained for only half the number of steps. This performance shows the potential of PoM as an alternative to MHA. Further, the qualitative results show successful fine-tuning enabling image generation at resolutions up to 1024 × 1024 on ImageNet. Moreover, some image classes slightly collapse due to limited training data at higher resolutions. Lastly, the results underscore PoM’s capability to serve as a drop-in replacement for MHA without any significant architectural modifications.

In conclusion, researchers introduced the Polynomial Mixer (PoM), a neural network building block designed to replace traditional attention mechanisms. By achieving linear computational complexity and proving its universal sequence-to-sequence approximation capabilities, PoM demonstrates significant potential across generative domains. It successfully generates competitive image and video models with enhanced resolution and generation speed compared to traditional MHA approaches. While the current implementation shows promise in image and video generation, the researchers identify promising future directions, particularly in long-duration high-definition video generation and multimodal large language models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.

 ‘
‘The post Polynomial Mixer (PoM): Overcoming Computational Bottlenecks in Image and Video Generation appeared first on MarkTechPost.



