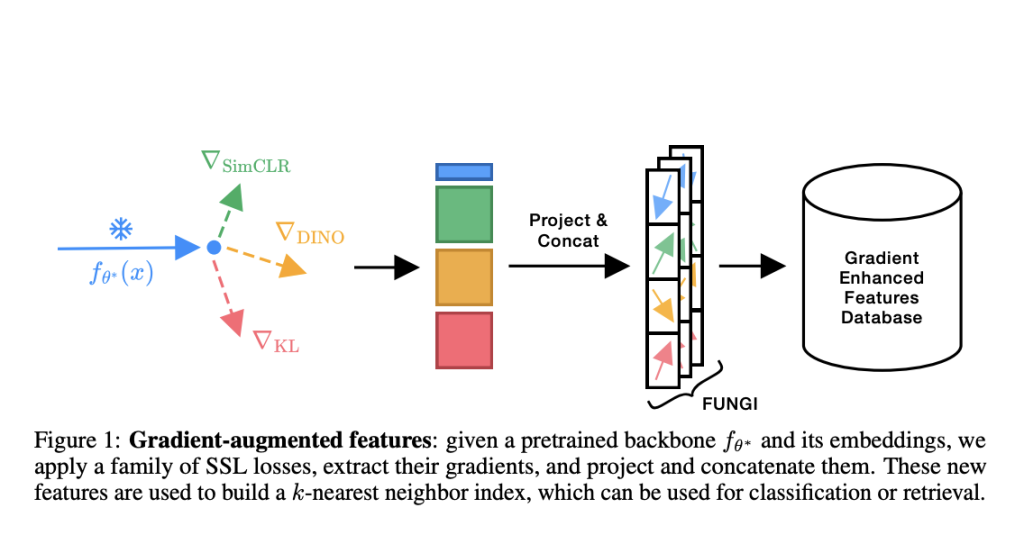


A central challenge in advancing deep learning-based classification and retrieval tasks is achieving robust representations without the need for extensive retraining or labeled data. Numerous applications depend on extensive, pre-trained models functioning as feature extractors; however, these pre-trained embeddings often fail to encapsulate the specific details required for optimal performance in the absence of fine-tuning. Retraining is often impractical in many areas bounded by limited computational resources or the lack of labeled data, for instance, in medical diagnostics and remote sensing. Therefore, developing a method that can enhance the performance of fixed representations without requiring retraining would be a great contribution to the field, as models will then be able to generalize well across lots of different tasks and domains.
Approaches such as k-nearest neighbor (kNN) algorithms, Vision Transformers (ViTs), and self-supervised learning (SSL) techniques like SimCLR and DINO have made considerable progress in learning representations by leveraging unlabeled data through pretext objectives. However, these methods are highly constrained and are limited by requirements that may need certain backbone architectures, heavy fine-tuning, or large amounts of labeled data to reduce generalizability. Many SSL techniques disregard gradient information that can potentially be present in frozen states, which might enhance the adaptability of learned representations to varied downstream applications by directly feeding important task-specific signals into embeddings.
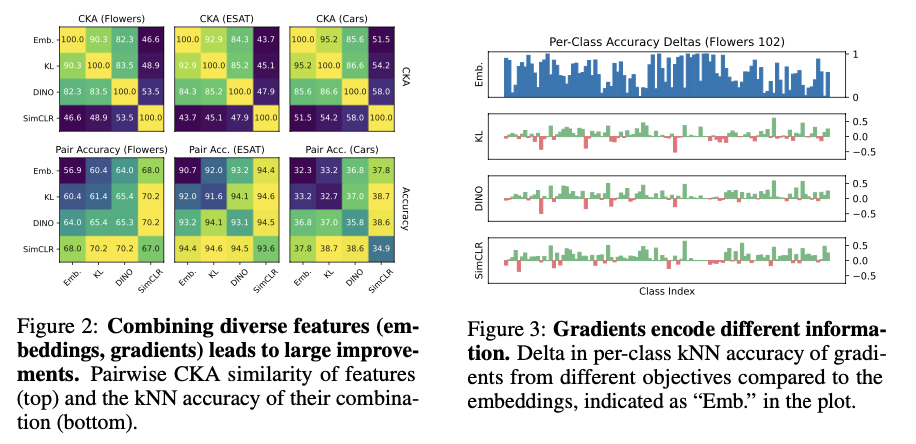
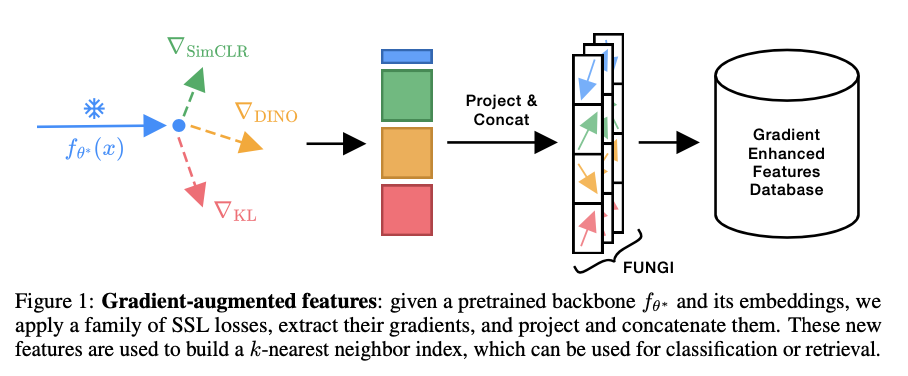
Researchers from the University of Amsterdam and valeo.ai introduce a streamlined and resource-efficient method called FUNGI (Features from UNsupervised GradIents), designed to enhance frozen embeddings by incorporating gradient information from self-supervised learning objectives. The new method is designed for frozen embedding improvement by using gradient information from self-supervised learning objectives. The method is effectively adaptive, as it can be applied with any pre-trained model without changing its parameters, making it flexible and computationally efficient. Using gradients based on varying SSL objectives, such as DINO, SimCLR, and KL divergence, FUNGI enrichment is carried out due to the fusion of complementary information from other approaches in multimodal learning. The gradients from the self-supervised learner and downscaled are concatenated to form model embeddings for highly discriminative feature vectors used for kNN classification. This efficient synthesis spells down the limits of current feature extraction techniques and allows performance to be greatly enhanced without needing further training.
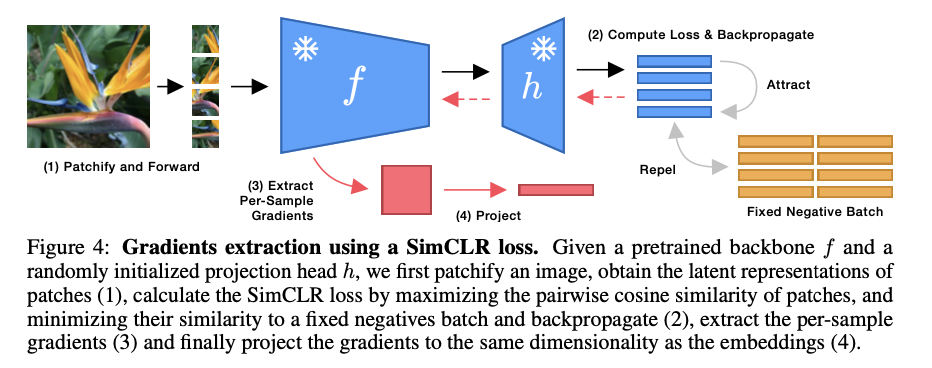
The FUNGI framework operates in three main stages: gradient extraction, dimensionality reduction, and concatenation with embeddings. It first computes gradients using the final hidden layers of Vision Transformer models from SSL losses to capture rich features that are task-relevant. Those high-dimensional gradients are then downsampled to match a target dimensionality with the aid of a binary random projection. Finally, the gradient downsampled is concatenated with the embeddings and then compressed further using the PCA application before becoming computationally efficient and highly informative feature sets. In doing this, it effectively augments frozen embeddings to enable greater performance in kNN retrieval and classification tasks.
FUNGI substantially improves across multiple benchmarks, including visual, text, and audio datasets. In kNN classification results, FUNGI shows a 4.4% relative increase over all ViT models with the largest increases reported over Flowers and CIFAR-100. In low-data (5-shot) settings, FUNGI achieves a 2.8% increase in accuracy, illustrating its effectiveness in data-scarce environments. It also covers retrieval-based semantic segmentation tasks on Pascal VOC, where FUNGI enhances baseline embeddings by up to 17% in segmentation accuracy. Experimental results show that the improvements provided by FUNGI are consistent over different datasets and models and very useful for high data efficiency and adaptability scenarios, thus becoming a powerful solution for applications with limited labeled data and computational resources.
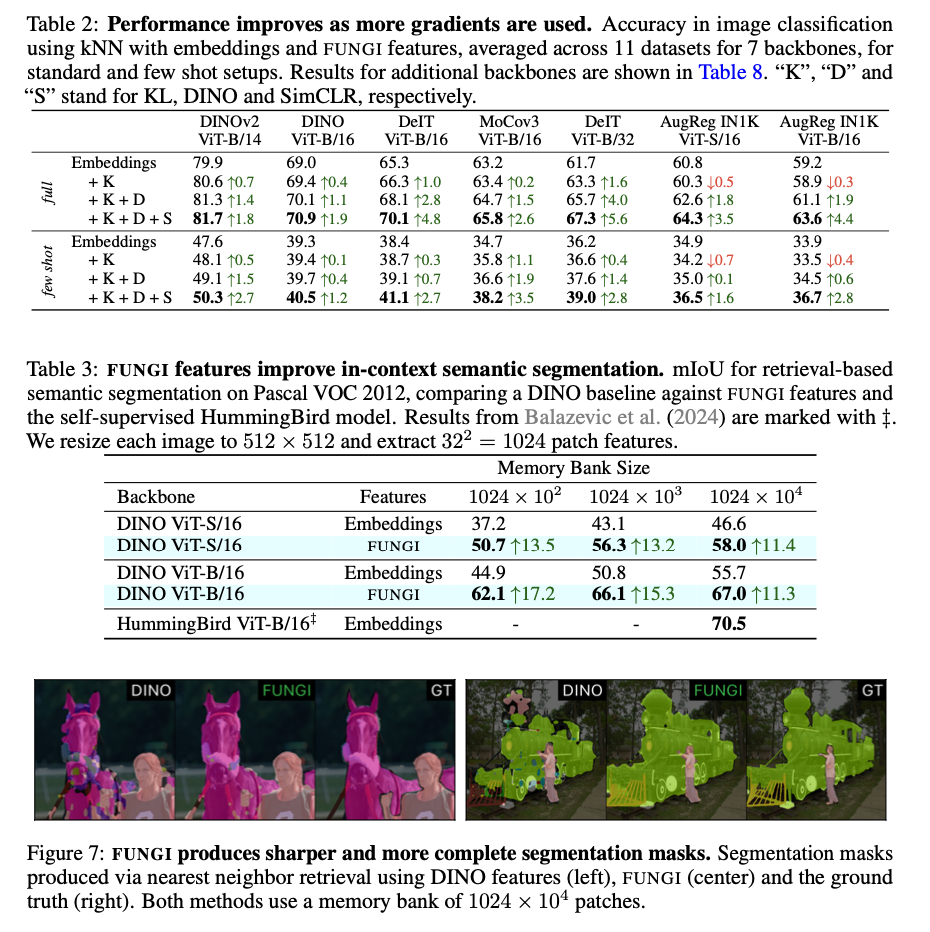
In conclusion, FUNGI provides an efficient means of enhancing the pre-trained model’s embeddings by ingesting unsupervised gradients from the SSL objectives. It enhances frozen model representations while preserving performance at higher levels of frozen levels when compared with other classification and retrieval tasks without retraining. Adaptability, computational efficiency, as well as strong low-data performance characterize a significant development in the area of representation learning where pre-trained models can run efficiently in scenarios of retraining is not practicable. This contribution represents a key advancement in the applicability of artificial intelligence to practical tasks characterized by limited labeled data and computational resources.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Intelligent Document Processing with GenAI in Financial Services and Real Estate Transactions
The post No Train, All Gain: Enhancing Deep Frozen Representations with Self-Supervised Gradients appeared first on MarkTechPost.