

Astronomical research has transformed dramatically, evolving from limited observational capabilities to sophisticated data collection systems that capture cosmic phenomena with unprecedented precision. Modern telescopes now generate massive datasets spanning multiple wavelengths, revealing intricate details of celestial objects. The current astronomical landscape produces an astounding volume of scientific data, with observational technologies capturing everything from minute stellar details to expansive galactic structures.
Machine learning applications in astrophysics face complex computational challenges that go beyond traditional data processing methods. The fundamental problem lies in integrating diverse astronomical observations across multiple modalities. Researchers must navigate heterogeneous data types, including multi-band imaging, spectroscopy, time-series measurements, and hyperspectral imaging.
Each observation type presents unique challenges:
- Sparse sampling
- Significant measurement uncertainties
- variations in instrumental responses that complicate comprehensive data analysis
Previous approaches to astronomical data management must be more cohesive and efficient. Most datasets were experiment-specific, with non-uniform storage and limited machine-learning optimization. Existing collections like the Galaxy Zoo project and PLAsTiCC light curve challenge provided limited insights, containing only 3.5 million simulated light curves or focused morphology classification datasets. These isolated approaches prevented researchers from developing comprehensive machine-learning models that could generalize across different astronomical observation types.
The research team from Instituto de Astrofisica de Canarias, Universidad de La Laguna, Massachusetts Institute of Technology, University of Oxford, University of Cambridge, Space Telescope Science Institute, Australian National University, Stanford University, UniverseTBD, Polymathic AI, Flatiron Institute, the University of California Berkeley, New York University, Princeton University, Columbia University, Université Paris-Saclay, Université Paris Cité, CEA, CNRS, AIM, University of Toronto, Center for Astrophysics, Harvard & Smithsonian, AstroAI, University of Pennsylvania, Aspia Space, Université de Montréal, Ciela Institute, Mila and Johns Hopkins University introduced the Multimodal Universe – a 100 TB astronomical dataset. This unprecedented collection aggregates 220 million stellar observations, 124 million galaxy images, and extensive spectroscopic data from multiple surveys, including Legacy Surveys, DESI, and JWST. The project aims to create a standardized, accessible platform that transforms machine learning capabilities in astrophysics.
The Multimodal Universe dataset represents an extraordinary compilation of astronomical data across six primary modalities. It includes 4 million SDSS-II galaxy observations, 1 million DESI galaxy spectra, 716,000 APOGEE stellar spectra, and 12,000 hyperspectral galaxy images from MaNGA. The dataset incorporates observations from diverse sources like Gaia, Chandra, and space telescopes, providing an unparalleled resource for astronomical machine-learning research.

Machine learning performance on this dataset achieved impressive zero-shot prediction performances: redshift predictions reached 0.986 R² using image and spectrum embeddings, while stellar mass predictions achieved 0.879 R² performance. Morphology classification tasks showed top-1 accuracy ranging from 73.5% to 89.3%, depending on neural network architectures and pretraining strategies. The ContrastiveCLIP approach even outperformed traditional supervised learning methods across multiple astronomical property predictions.
Key research insights highlight the Multimodal Universe’s potential:
- Compiled 100 TB of astronomical data across six observation modalities
- Integrated 220 million stellar observations and 124 million galaxy images
- Created cross-matching utilities for diverse astronomical datasets
- Developed machine learning models with zero-shot prediction accuracies up to 0.986 R²
- Established a community-driven, extensible data management platform
- Provided standardized access to astronomical observations through Hugging Face datasets
- Demonstrated advanced machine-learning capabilities across multiple astronomical tasks
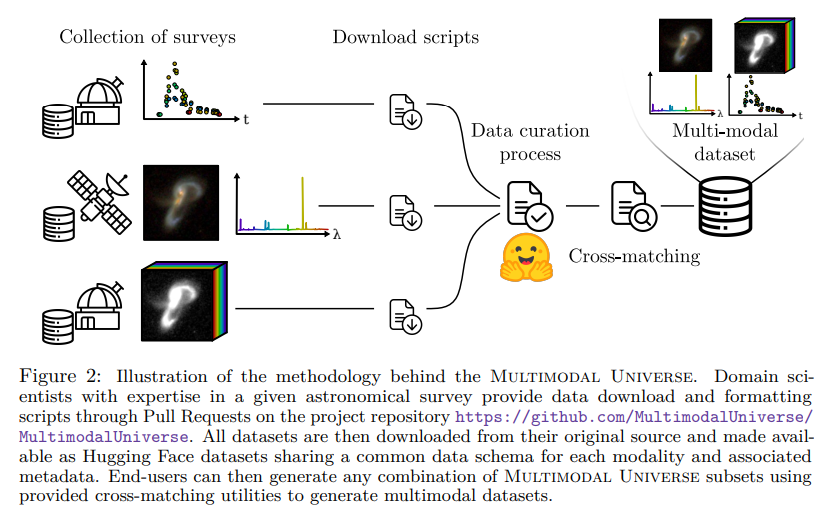
In conclusion, the Multimodal Universe dataset is a pioneering resource, providing over 100 terabytes of diverse astronomical data to advance machine learning research. It supports many astrophysical applications, including multi-channel images, spectra, time-series data, and hyperspectral images. This dataset addresses the barriers to scientific ML development by standardizing data formats and facilitating easy access through platforms like Hugging Face and GitHub.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 60k+ ML SubReddit.
 [Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
[Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
The post Multimodal Universe Dataset: A Multimodal 100TB Repository of Astronomical Data Empowering Machine Learning and Astrophysical Research on a Global Scale appeared first on MarkTechPost.



