

Large Multimodal Models (LMMs) excel in many vision-language tasks, but their effectiveness needs to improve in cross-cultural contexts. This is because they need to counterbalance the bias in their training datasets and methodologies, preventing a rich array of cultural elements from being properly represented in image captions. Overcoming this limitation will help to make artificial intelligence more robust at dealing with culturally sensitive tasks and promote inclusivity as it increases its applicability across global environments.
Single-agent LMMs, such as BLIP-2 and LLaVA-13b, have been the predominant tools for image captioning. However, they need more diverse training data to incorporate cultural depth. These models need to capture the subtleties of multiple cultural perspectives, and thus, the outputs appear stereotypical and unspecific. Besides, the traditional metrics of measurement, such as accuracy and F1 scores, do not capture the depth of cultural representation but instead emphasize the overall correctness. This methodological weakness hinders the ability of these models to produce captions that are meaningful and significant to different audiences.
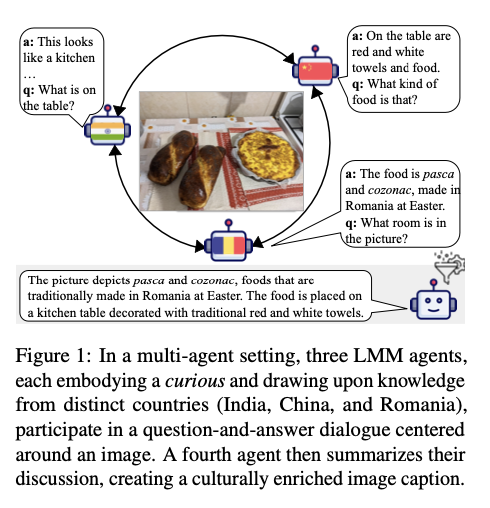
To address these challenges, researchers from the University of Michigan and Santa Clara University developed MosAIC, an innovative framework for enhancing cultural image captioning through collaborative interactions. This method utilizes a set of several agents who all have their own specific cultural identities but take part in organized, moderated discussions between them. Their dialogue is collected and condensed by a summarizing agent into a culturally enhanced caption. The framework uses a dataset of 2,832 captions from three different cultures: China, India, and Romania, sourced from GeoDE, GD-VCR, and CVQA. It also uses an innovative culture-adaptable evaluation metric to evaluate the representation of cultural components in the captions, thus providing a comprehensive tool for assessing output quality. This sets the benchmark in allowing agent-specific expertise and encouraging iterative learning toward better captions that are accurate and more culturally deep.
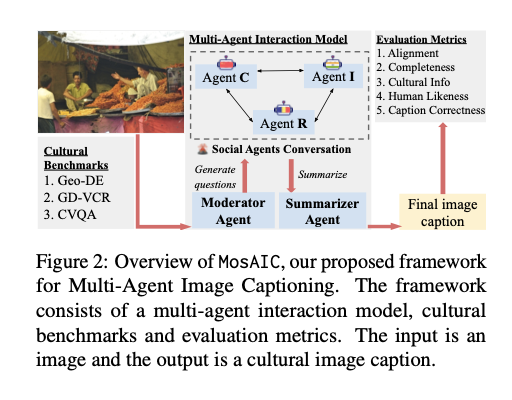
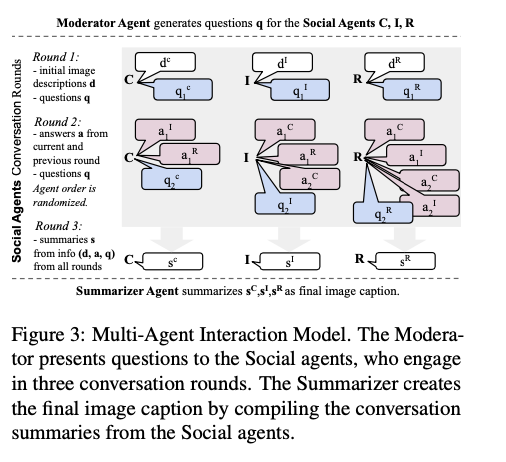
The MosAIC system operates through a multi-round interaction mechanism where agents first independently analyze images and then engage in collaborative discussions to refine their interpretations. Because each agent brings its unique cultural perspective into the discourse, it contributes richness to holistic image representation. Elaborate methodologies, including Chain-of-Thought prompting, enable agents to create output that is well-structured and coherent. The model includes memory management systems that are used to track the discussion over several rounds without bias. The use of geographically diverse datasets ensures that the generated captions encompass diverse cultural perspectives, thus making the framework applicable in multiple contexts.
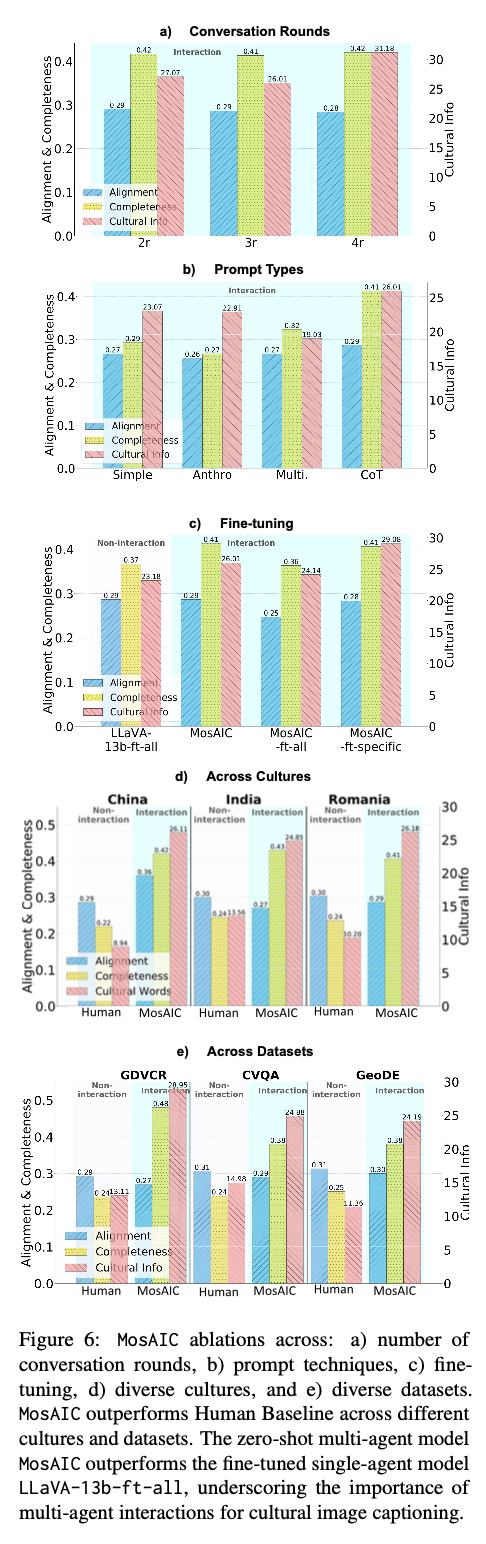
The MosAIC framework significantly outperforms single-agent models in producing captions that are deeper and more culturally complete. It captures diverse cultural terms and integrates them very well into its outputs, achieving higher scores on cultural representation while remaining consistent with the content of the images. Human evaluations further validate its success, showing that its captions align closely with cultural contexts and far surpass conventional models in detail and inclusivity. The cooperative framework that supports this system is crucial for improving its capability to reflect cultural nuance and represents a milestone development in culturally conscious artificial intelligence.
MosAIC addresses the critical issue of Western-centric bias in LMMs by introducing a collaborative framework for cultural image captioning. It achieves this through innovative interaction strategies, novel datasets, and specialized evaluation metrics that may be used to produce captions at once contextually accurate and culturally rich. This work forms a revolutionary step in the field, setting a foundation for further advancements in creating inclusive and globally relevant AI systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….The post MosAIC: A Multi-Agent AI Framework for Cross-Cultural Image Captioning appeared first on MarkTechPost.



