

LLMs face challenges in continual learning due to the limitations of parametric knowledge retention, leading to the widespread adoption of RAG as a solution. RAG enables models to access new information without modifying their internal parameters, making it a practical approach for real-time adaptation. However, traditional RAG frameworks rely heavily on vector retrieval, which limits their ability to capture complex relationships and associations in knowledge. Recent advancements have integrated structured data, such as knowledge graphs, to enhance reasoning capabilities, improving sense-making and multi-hop connections. While these methods offer improvements in contextual understanding, they often compromise performance on simpler factual recall tasks, highlighting the need for more refined approaches.
Continual learning strategies for LLMs typically fall into three categories: continual fine-tuning, model editing, and non-parametric retrieval. Fine-tuning periodically updates model parameters with new data but is computationally expensive and prone to catastrophic forgetting. Model editing modifies specific parameters for targeted knowledge updates, but its effects remain localized. In contrast, RAG dynamically retrieves relevant external information at inference time, allowing for efficient knowledge updates without altering the model’s parameters. Advanced RAG frameworks, such as GraphRAG and LightRAG, enhance retrieval by structuring knowledge into graphs, improving the model’s ability to synthesize complex information. HippoRAG 2 refines this approach by leveraging structured retrieval while minimizing errors from LLM-generated noise, balancing sense-making and factual accuracy.
HippoRAG 2, developed by researchers from The Ohio State University and the University of Illinois Urbana-Champaign, enhances RAG by improving factual recall, sense-making, and associative memory. Building upon HippoRAG’s Personalized PageRank algorithm, it integrates passages more effectively and refines online LLM utilization. This approach achieves a 7% improvement in associative memory tasks over leading embedding models while maintaining strong factual and contextual understanding. Extensive evaluations show its robustness across various benchmarks, outperforming existing structure-augmented RAG methods. HippoRAG 2 significantly advances non-parametric continual learning, bringing AI systems closer to human-like long-term memory capabilities.
HippoRAG 2 is a neurobiologically inspired long-term memory framework for LLMs, enhancing the original HippoRAG by improving context integration and retrieval. It comprises an artificial neocortex (LLM), a parahippocampal region encoder, and an open knowledge graph (KG). Offline, an LLM extracts triples from passages, linking synonyms and integrating conceptual and contextual information. Online, queries are mapped to relevant triples using embedding-based retrieval, followed by Personalized PageRank (PPR) for context-aware selection. HippoRAG 2 introduces recognition memory for filtering triples and deeper contextualization by linking queries to triples, enhancing multi-hop reasoning and improving retrieval accuracy for QA tasks.
The experimental setup includes three baseline categories: (1) classical retrievers such as BM25, Contriever, and GTR, (2) large embedding models like GTE-Qwen2-7B-Instruct, GritLM-7B, and NV-Embed-v2, and (3) structure-augmented RAG models, including RAPTOR, GraphRAG, LightRAG, and HippoRAG. The evaluation spans three key challenge areas: simple QA (factual recall), multi-hop QA (associative reasoning), and discourse understanding (sense-making). Metrics include passage recall@5 for retrieval and F1 scores for QA. HippoRAG 2, leveraging Llama-3.3-70B-Instruct and NV-Embed-v2, outperforms prior models, particularly in multi-hop tasks, demonstrating enhanced retrieval and response accuracy with its neuropsychology-inspired approach.
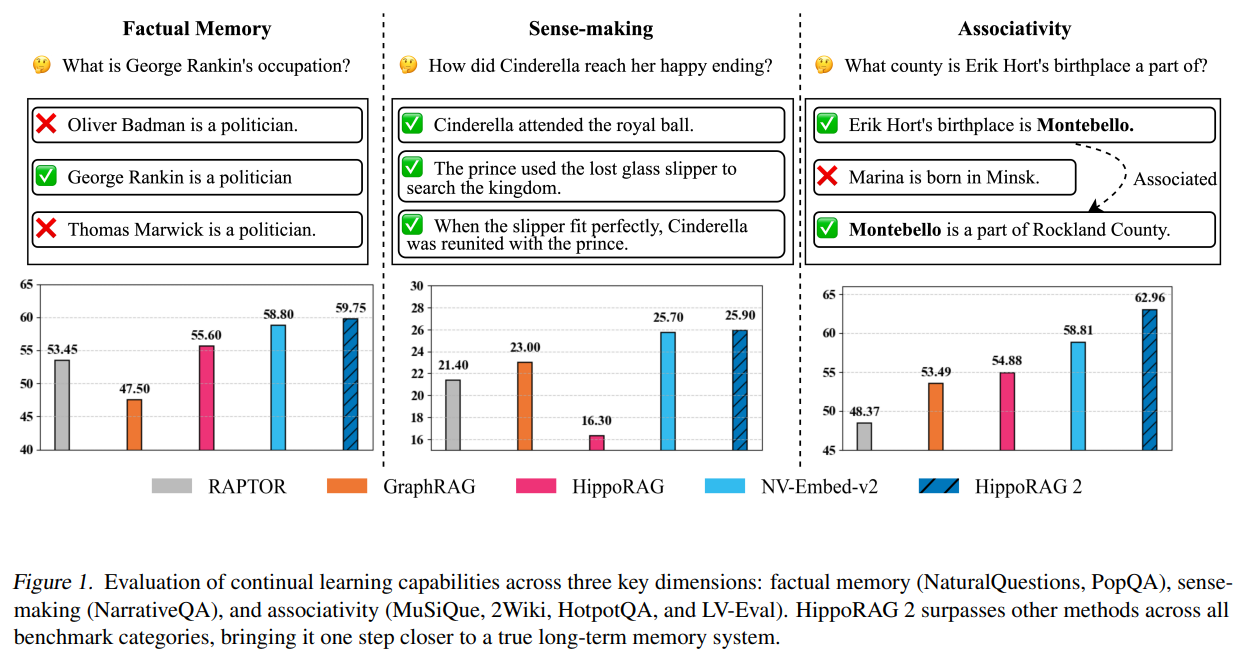
In conclusion, the ablation study evaluates the impact of linking, graph construction, and triple filtering methods, showing that deeper contextualization significantly improves HippoRAG 2’s performance. The query-to-triple approach outperforms others, enhancing Recall@5 by 12.5% over NER-to-node. Adjusting reset probabilities in PPR balances phrase and passage nodes, optimizing retrieval. HippoRAG 2 integrates seamlessly with dense retrievers, consistently outperforming them. Qualitative analysis highlights superior multi-hop reasoning. Overall, HippoRAG 2 enhances retrieval and reasoning by leveraging Personalized PageRank, deeper passage integration, and LLMs, offering advancements in long-term memory modeling. Future work may explore graph-based retrieval for improved episodic memory in conversations.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.

The post HippoRAG 2: Advancing Long-Term Memory and Contextual Retrieval in Large Language Models appeared first on MarkTechPost.