

Transformers have been the foundation of large language models (LLMs), and recently, their application has expanded to search problems in graphs, a foundational domain in computational logic, planning, and AI. Graph search is integral to solving tasks requiring systematically exploring nodes and edges to find connections or paths. Despite transformers’ apparent adaptability, their ability to efficiently perform graph search remains an open question, especially when scaling to complex and large datasets.
Graphs offer a way to present complex data, but they come with challenges unlike others. In graph search tasks, the structured nature of the data and the computational demands required to explore paths between nodes make it challenging and require efficient algorithms. Especially Large-scale graphs amplify this complexity, requiring algorithms to navigate exponentially growing search spaces. Current transformer architectures demonstrate limited success, often relying on heuristic approaches that compromise their robustness and generalizability. The difficulty increases with graph size as transformers must identify patterns or algorithms that work universally across datasets. This limitation raises concerns about their scalability and capacity to generalize to diverse search scenarios.

Attempts to address these limitations have mainly focused on leveraging chain-of-thought prompting and similar techniques, enabling models to break down tasks into incremental steps. While this approach is promising for smaller and less complex graphs, it falls short for larger graphs with more intricate connectivity patterns. Also, increasing model parameters or adding more training data does not consistently improve performance. For example, even with sophisticated prompting methods, transformers exhibit errors and inefficiencies when identifying the correct path in expansive graph structures. These challenges need a shift in how transformers are trained and optimized for graph search tasks.
In a recent study, researchers from Purdue University, New York University, Google, and Boston University introduced a training framework to enhance transformers’ graph search capabilities. To ensure comprehensive training coverage, the researchers employed an innovative strategy using directed acyclic graphs (DAGs) as a testbed and balanced data distributions. By designing datasets that discouraged reliance on heuristics, the team aimed to enable transformers to learn robust algorithms. The training involved systematically generating examples with varying levels of complexity as it allowed the model to progressively build its understanding of graph connectivity.
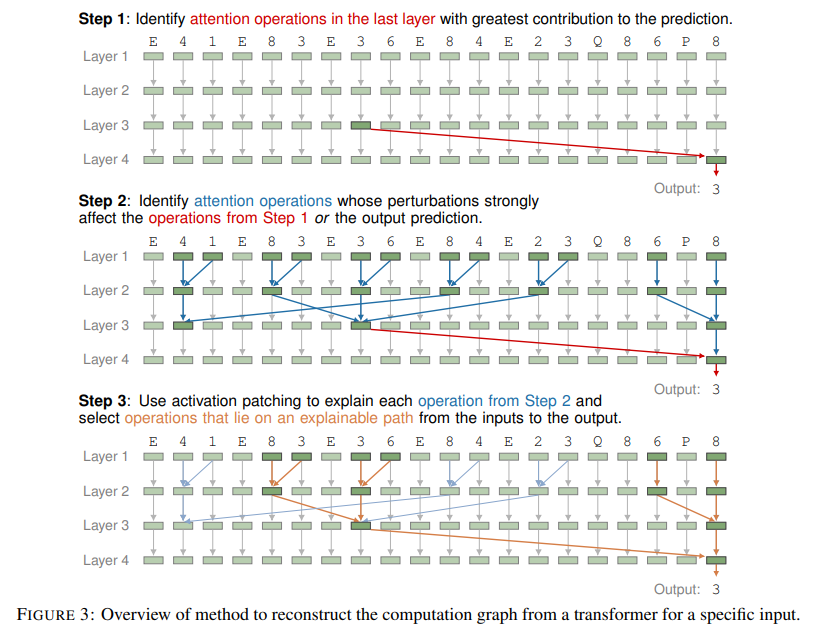
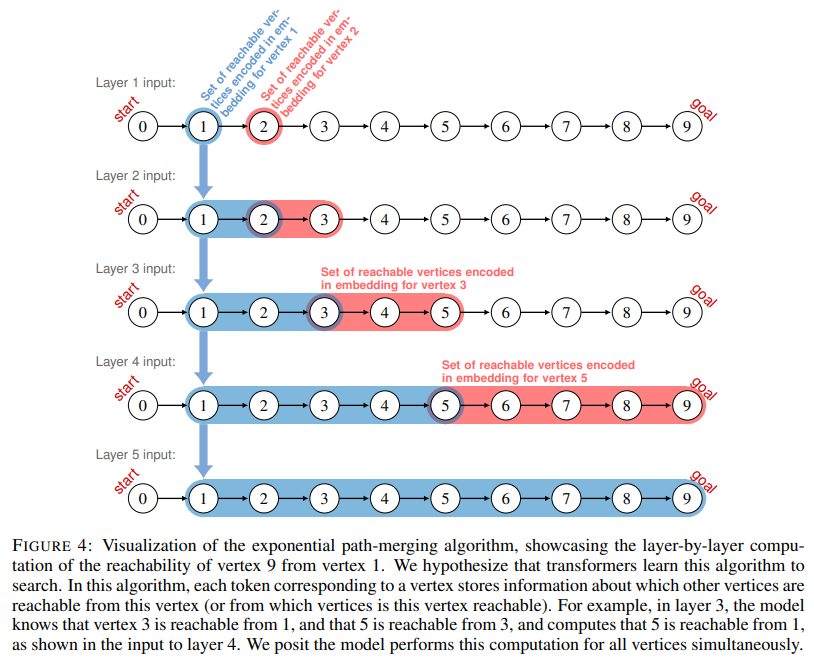
The training methodology focused on a balanced distribution of graphs, ensuring uniform representation of scenarios with different lookaheads (lookahead refers to the number of steps a model must search to connect the start vertex to the goal vertex in a graph) and the number of steps required to find a path between two nodes. The transformers were trained to compute sets of reachable vertices exponentially, layer by layer, effectively simulating an “exponential path-merging” algorithm. This technique allowed the embeddings to encode detailed information about connectivity, enabling the model to explore paths systematically. The researchers analyzed the transformers’ internal operations using mechanistic interpretability techniques to validate this approach. By reconstructing computation graphs, they demonstrated how attention layers aggregated and processed information to identify paths in DAGs.
The results of the study were a mix of some positives and negatives. Transformers trained on the balanced distribution achieved near-perfect accuracy for small graphs, even with lookaheads extending to 12 steps. However, performance declined significantly as graph sizes increased. For instance, models trained on graphs with lookahead constraints of up to 12 struggled to generalize to larger lookaheads beyond this range. Accuracy on larger graphs dropped below 50% for lookaheads exceeding 16 steps. With an input size of 128 tokens and a 6-layer architecture, transformers could not reliably handle expansive graphs. The study also highlighted that scaling model size did not resolve these issues. Larger models showed no consistent improvement in handling complex search tasks, underscoring the inherent limitations of the transformer architecture.
The researchers also explored alternate methods, such as depth-first search (DFS) and selection-inference prompting, to evaluate whether intermediate steps could enhance performance. While these approaches simplified certain tasks, they needed to fundamentally improve the transformers’ ability to handle larger graph sizes. The models struggled with graphs exceeding 45 vertices, even when trained on distributions designed to emphasize exploration. Also, increasing the scale of training data or the number of parameters did not lead to substantial gains, emphasizing that more than traditional scaling strategies are required to overcome these challenges.
Some of the key takeaways from the research include the following:
- Models trained on balanced distributions that eliminated reliance on shortcuts outperformed those trained on naive or heuristic-driven datasets. This finding underscores the importance of carefully curating training data to ensure robust learning.
- The researchers identified the “exponential path-merging” algorithm as a key process by analyzing transformers’ internal workings. This understanding could guide future architectural improvements and training methodologies.
- The models exhibited increasing difficulty as graph sizes grew, with accuracy declining significantly for larger lookaheads and graphs beyond 31 nodes.
- Increasing model parameters or the size of training datasets did not resolve the limitations, indicating that architectural changes or novel training paradigms are necessary.
- Alternate architectures, such as looped transformers, and advanced training methods, like curriculum learning, may offer potential solutions. Integrating mechanistic insights could also lead to better algorithmic understanding and scalability.

In conclusion, this research comprehensively analyzes transformers’ capabilities and limitations in performing graph search tasks. By demonstrating the effectiveness of tailored training distributions and uncovering the internal algorithms used by the models, the study offers valuable insights into transformers’ computational behavior. However, the challenges of scaling to larger graphs and achieving robust generalization highlight the need for innovative approaches. These findings emphasize the need for alternate architectures or advanced training approaches to enhance scalability and robustness in graph-based reasoning tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 [Must Subscribe]: Subscribe to our newsletter to get trending AI research and dev updates
[Must Subscribe]: Subscribe to our newsletter to get trending AI research and dev updates
The post Do Transformers Truly Understand Search? A Deep Dive into Their Limitations appeared first on MarkTechPost.



