

Recently, AI agents have demonstrated very promising developments in automating mathematical theorem proving and code correctness verification using tools like Lean. Such tools pair code with specifications and proofs to ensure it meets its intended requirements, offering very strong safeguards in safety-critical applications. Artificial Intelligence has demonstrated that it can enable the fundamental steps of solution development, namely coding, specifying, and proving, through large language models. While these advances promise much, fully automating program verification remains challenging.
Traditionally, mathematical theorem proving has relied on tools like Lean, which train models on datasets such as Mathlib to solve problems using specific definitions and strategies. However, these tools have struggled to adapt to program verification, which requires entirely different methods and approaches. While machine learning has improved automation in systems like Coq and Isabelle, similar advancements for Lean in program verification are still missing. Other tools like Dafny and Verus, as well as benchmarks like miniF2F and CoqGym, offer alternatives. Still, they have not been able to fully address the challenges of adapting mathematical theorem-proving methods to the needs of program verification.
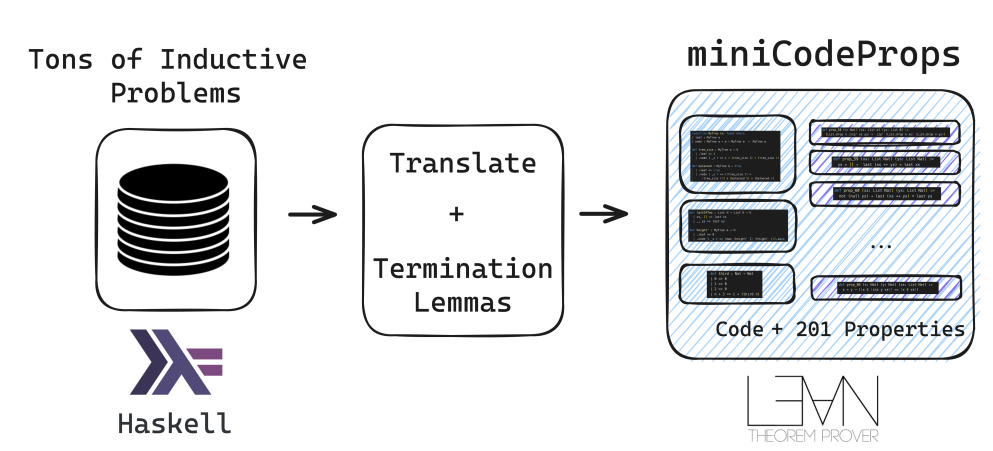
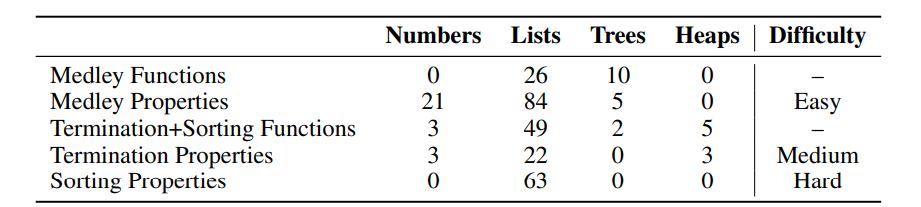
To solve this, researchers from Carnegie Mellon University proposed miniCodeProps, a benchmark containing 201 program specifications in the Lean proof assistant, to address the challenge of automatically generating proofs for programs and their specifications. miniCodeProps contained simple, self-contained programs like lists, natural numbers, and binary trees, with varying difficulty levels for proving. The dataset, divided into three categories—intuitive properties of lists, trees, and numbers (medley), termination lemmas for recursive functions (termination), and properties of nonstandard sorting algorithms (sorting)—included 201 theorem statements. The functions primarily operated on linked lists, with some involving natural numbers and binary trees. These properties were categorized by difficulty: easy (medley), medium (termination), and hard (sorting). Termination lemmas required proving recursion termination, which was critical for Lean 4’s use. The dataset, available in jsonlines format, included essential details such as the proof state and dependencies for each theorem. Examples like the zip over concatenation property and sorting properties highlighted the challenge of proving these properties, especially for more complex sorting algorithms.
The evaluation of miniCodeProps focused on two main tasks: full-proof generation and tactic-by-tactic generation. In full-proof generation, models were tested on their ability to generate complete proofs for given specifications. For tactic-by-tactic generation, models were evaluated based on their ability to suggest the next appropriate tactic from the current proof state, testing incremental reasoning. The evaluation also considered the difficulty levels of the proofs, ranging from simple properties of lists and numbers to complex termination and sorting algorithm properties, measuring both efficiency and correctness in proof generation or tactic application.
The results indicated that neural theorem provers, such as GPT-4o, performed well on simpler tasks, achieving a 75.6% success rate on medley properties. However, performance on the harder tasks, such as termination and sorting, was lower, at 4.34% and 6.96%, respectively. The Mathlib-trained model ntp-ctx-1.3B demonstrated similar efficiency to GPT-4o, suggesting the potential for domain-specific verifiers to show further promise. MiniCodeProps provides a framework for improving automated theorem-proving agents for code verification, supporting human engineers, and offering additional guarantees through diverse reasoning approaches.

In the end, the proposed miniCodeProps is a valuable benchmark that can be used to advance automated ITP-based code verification. It contains problems from a range of Inductive problem datasets, which enables stepwise progress in checking program properties. However, the method showed limitations and cannot effectively solve complicated problems. MiniCodeProps can potentially drive advancements in verification agents and serve as a baseline for evaluating new approaches in automated code verification.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….The post CMU Researchers Propose miniCodeProps: A Minimal AI Benchmark for Proving Code Properties appeared first on MarkTechPost.



