

Large language models (LLMs) have transformed the landscape of natural language processing, becoming indispensable tools across industries such as healthcare, education, and technology. These models perform complex tasks, including language translation, sentiment analysis, and code generation. However, their exponential growth in scale and adoption has introduced significant computational challenges. Each task often requires fine-tuned versions of these models, leading to high memory and energy demands. Efficiently managing the inference process in environments with concurrent queries for diverse tasks is crucial for sustaining their usability in production systems.
Inference clusters serving LLMs face fundamental issues of workload heterogeneity and memory inefficiencies. Current systems encounter high latency due to frequent adapter loading and scheduling inefficiencies. Adapter-based fine-tuning techniques, such as Low-Rank Adaptation (LoRA), enable models to specialize in tasks by modifying smaller portions of the base model parameters. While LoRA substantially reduces memory requirements, it introduces new challenges. These include increased contention on memory bandwidth during adapter loads and delays from head-of-line blocking when requests of varying complexities are processed sequentially. These inefficiencies limit the scalability and responsiveness of inference clusters under heavy workloads.

Existing solutions attempt to address these challenges but need to catch up in critical areas. For instance, methods like S-LoRA store base model parameters in GPU memory and load adapters on-demand from host memory. This approach leads to performance penalties due to adapter fetch times, particularly in high-load scenarios where PCIe link bandwidth becomes a bottleneck. Scheduling policies such as FIFO (First-In, First-Out) and SJF (Shortest-Job-First) have been explored to manage the diversity in request sizes, but both approaches fail under extreme load. FIFO often causes head-of-line blocking for smaller requests, while SJF leads to starvation of longer requests, resulting in missed service level objectives (SLOs).
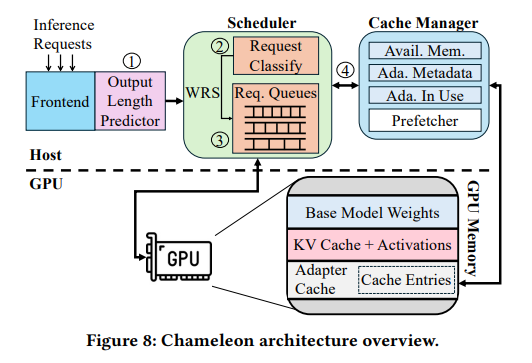
Researchers from the University of Illinois Urbana-Champaign and IBM Research introduced Chameleon, an innovative LLM inference system designed to optimize environments with numerous task-specific adapters. Chameleon combines adaptive caching and a sophisticated scheduling mechanism to mitigate inefficiencies. It employs GPU memory more effectively by caching frequently used adapters, thus reducing the time required for adapter loading. Also, the system uses a multi-level queue scheduling policy that dynamically prioritizes tasks based on resource needs and execution time.
Chameleon leverages idle GPU memory to cache popular adapters, dynamically adjusting cache size based on system load. This adaptive cache eliminates the need for frequent data transfers between CPU and GPU, significantly reducing contention on the PCIe link. The scheduling mechanism categorizes requests into size-based queues and allocates resources proportionally, ensuring no task is starved. This approach accommodates heterogeneity in task sizes and prevents smaller requests from being blocked by larger ones. The scheduler dynamically recalibrates queue priorities and quotas, optimizing performance under varying workloads.
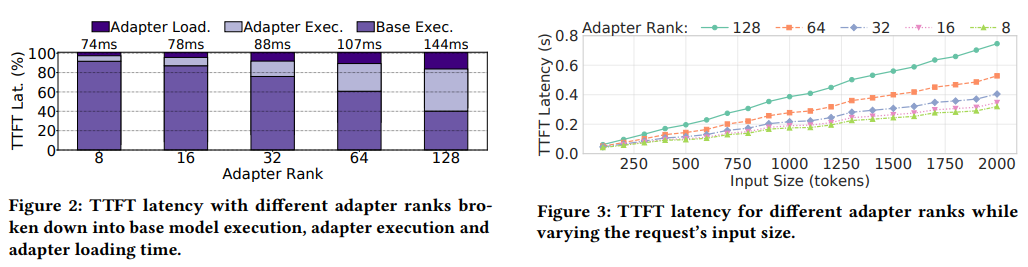
The system was evaluated using real-world production workloads and open-source LLMs, including the Llama-7B model. Results show that Chameleon reduces the P99 time-to-first-token (TTFT) latency by 80.7% and P50 TTFT latency by 48.1%, outperforming baseline systems like S-LoRA. Throughput improved by 1.5 times, allowing the system to handle higher request rates without violating SLOs. Notably, Chameleon demonstrated scalability, efficiently handling adapter ranks ranging from 8 to 128 while minimizing the latency impact of larger adapters.
Key Takeaways from the Research:
- Performance Gains: Chameleon reduced tail latency (P99 TTFT) by 80.7% and median latency (P50 TTFT) by 48.1%, significantly improving response times under heavy workloads.
- Enhanced Throughput: The system achieved 1.5x higher throughput than baseline methods, allowing for more concurrent requests.
- Dynamic Resource Management: Adaptive caching effectively utilized idle GPU memory, dynamically resizing the cache based on system demand to minimize adapter reloads.
- Innovative Scheduling: The multi-level queue scheduler eliminated head-of-line blocking and ensured fair resource allocation, preventing starvation of larger requests.
- Scalability: Chameleon efficiently supported adapter ranks from 8 to 128, demonstrating its suitability for diverse task complexities in multi-adapter settings.
- Broader Implications: This research sets a precedent for designing inference systems that balance efficiency and scalability, addressing real-world production challenges in deploying large-scale LLMs.

In conclusion, Chameleon introduces significant advancements for LLM inference in multi-adapter environments. Leveraging adaptive caching and a non-preemptive multi-level queue scheduler optimizes memory utilization and task scheduling. The system efficiently addresses adapter loading and heterogeneous request handling issues, delivering substantial performance improvements.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.

 ‘
‘The post Chameleon: An AI System for Efficient Large Language Model Inference Using Adaptive Caching and Multi-Level Scheduling Techniques appeared first on MarkTechPost.



