

In recent times, Retrieval-augmented generation (RAG) has become popular due to its ability to solve challenges using Large Language Models, such as hallucinations and outdated training data. A RAG pipeline consists of two components: a retriever and a reader. The retriever component finds useful information from an exterior knowledge base, which is then included alongside a query in a prompt for the reader model. This process has been used as an effective alternative to expensive fine-tuning as it helps to reduce errors made by LLMs. However, it is unclear how much each part of an RAG pipeline contributes to its performance on specific tasks.
Currently, retrieval models use Dense vector embedding models due to their better performance than older methods as they rely on word frequencies. These models use nearest-neighbor search algorithms to find documents matching a query, with most dense retrievers encoding each document as a single vector. Advanced multi-vector models like ColBERT allow better interactions between document and query terms, potentially generalizing better to new datasets. However, dense vector embeddings are inefficient, especially with high-dimensional data, slowing down searches in large databases. The RAG pipelines use an approximate nearest neighbor (ANN) search to improve this by sacrificing some accuracy for faster results. However, no clear guidance exists on configuring ANN search to balance speed and accuracy.
A group of researchers from the University of Colorado Boulder and Intel Labs conducted detailed research on optimizing RAG pipelines for common tasks such as Question Answering (QA). Focusing on understanding the impact of retrieval on downstream performance in RAG pipelines, pipelines were evaluated in which the retriever and LLM components were separately trained. It was found that the approach avoids the high resource costs of end-to-end training and clarifies the retriever’s contribution.
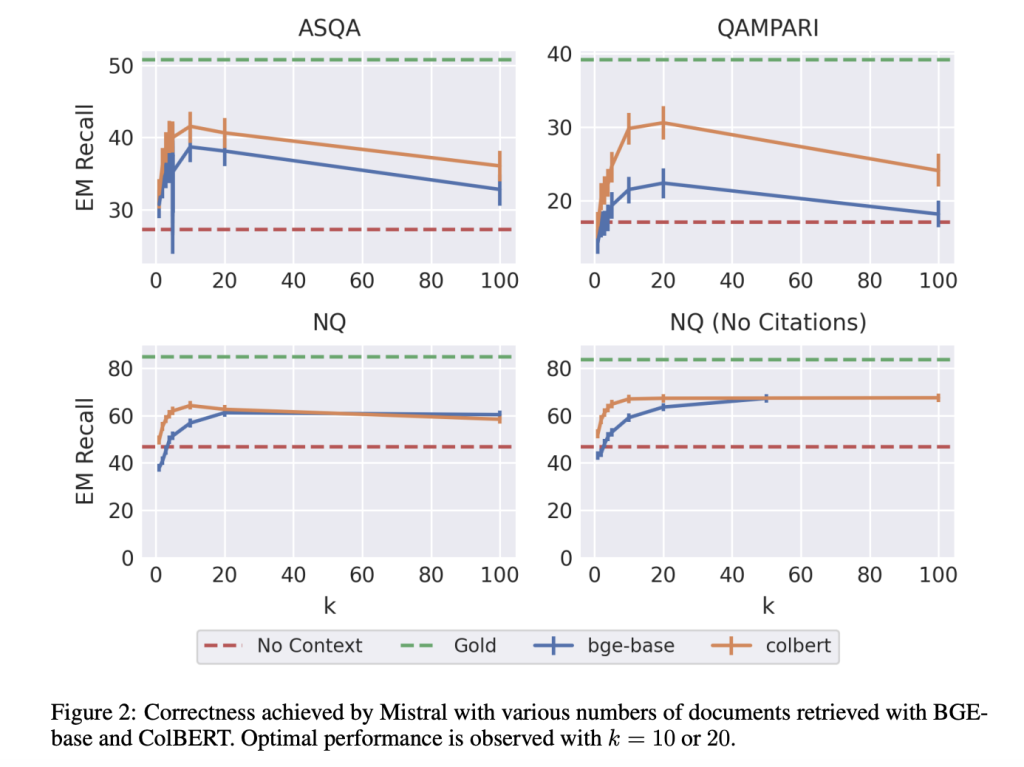
Experiments were conducted to evaluate the performance of two instruction-tuned LLMs, LLaMA and Mistral, in Retrieval-Augmented Generation (RAG) pipelines without fine-tuning or further training. The evaluation mainly focused on standard QA and attributed QA tasks, where models generated answers using retrieved documents, and it included specific document citations in the case of attributed QA. Dense retrieval models such as BGE-base and ColBERTv2 were used to leverage efficient ANN search for dense embeddings. The tested datasets included ASQA, QAMPARI, and Natural Questions (NQ), designed to assess retrieval and generation capabilities. Retrieval metrics relied on recall (retriever and search recall), while QA accuracy was measured using exact match recall, and established frameworks assessed citation quality through citation recall and precision. Confidence intervals were computed using bootstrapping to determine statistical significance across various queries.
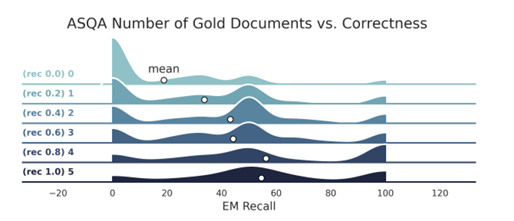
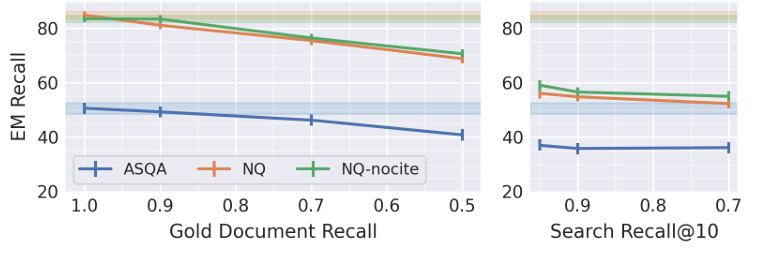
After evaluating the performance, the researchers found that retrieval generally improves performance, with ColBERT slightly outperforming BGE by a small margin. The analysis showed optimal correctness with 5-10 retrieved documents for Mistral, and 4-10 for LLaMA was achieved depending on the dataset. Notably, adding a citation prompt only significantly impacted results when the number of retrieved documents (k) exceeded 10. For some documents, the citation precision was highest, and adding more led to too many citations. Including gold documents greatly improved QA performance, and lowering the search recall from 1.0 to 0.7 had only a small impact. Thus, the researchers found that reducing the accuracy of the approximate nearest neighbor (ANN) search in the retriever has minimal effects on task performance. Adding noise to retrieval results also leads to a decline in performance. And the configuration was not found to surpass the gold standard.
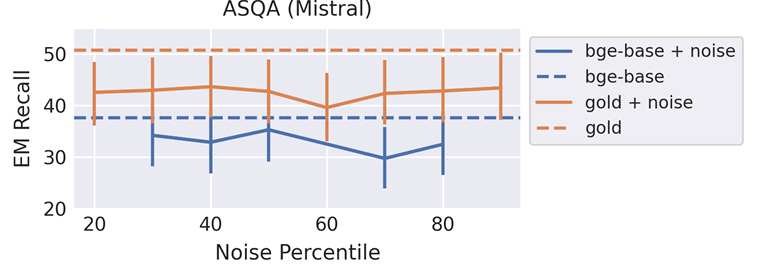
In conclusion, this research provided useful insights on improving retrieval strategies for RAG pipelines and highlighted the importance of retrievers in boosting performance and efficiency, especially for QA tasks. It also showed that injecting noisy documents alongside gold or retrieved documents degrades correctness compared to the gold ceiling. In the future, the generality of this research’s findings can be tested in other settings and can serve as a baseline for future research in the field of RAG pipelines!
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Intelligent Document Processing with GenAI in Financial Services and Real Estate Transactions– From Framework to Production
The post Balancing Accuracy and Speed in RAG Systems: Insights into Optimized Retrieval Techniques appeared first on MarkTechPost.