

AI has made significant strides in developing large language models (LLMs) that excel in complex tasks such as text generation, summarization, and conversational AI. Models like LaPM 540B and Llama-3.1 405B demonstrate advanced language processing abilities, yet their computational demands limit their applicability in real-world, resource-constrained environments. These LLMs are often cloud-based, requiring extensive GPU memory and hardware, which raises privacy concerns and prevents immediate on-device deployment. In contrast, small language models (SLMs) are being explored as an efficient and adaptable alternative, capable of performing domain-specific tasks with lower computational requirements.
The primary challenge with LLMs, as addressed by SLMs, is their high computational cost and latency, particularly for specialized applications. For instance, models like Llama-3.1, containing 405 billion parameters, require over 200 GB of GPU memory, rendering them impractical for deployment on mobile devices or edge systems. In real-time scenarios, these models suffer from high latency; processing 100 tokens on a Snapdragon 685 mobile processor with the Llama-2 7B model, for example, can take up to 80 seconds. Such delays hinder real-time applications, making them unsuitable for settings like healthcare, finance, and personal assistant systems that demand immediate responses. The operational expenses associated with LLMs also restrict their use, as their fine-tuning for specialized fields such as healthcare or law requires significant resources, limiting accessibility for organizations without large computational budgets.
Various methods currently address these limitations, including cloud-based APIs, data batching, and model pruning. However, these solutions often fall short, as they must fully alleviate high latency issues, dependence on extensive infrastructure, and privacy concerns. Techniques like pruning and quantization can reduce model size but frequently decrease accuracy, which is detrimental for high-stakes applications. The absence of scalable, low-cost solutions for fine-tuning LLMs for specific domains further emphasizes the need for an alternative approach to deliver targeted performance without prohibitive costs.
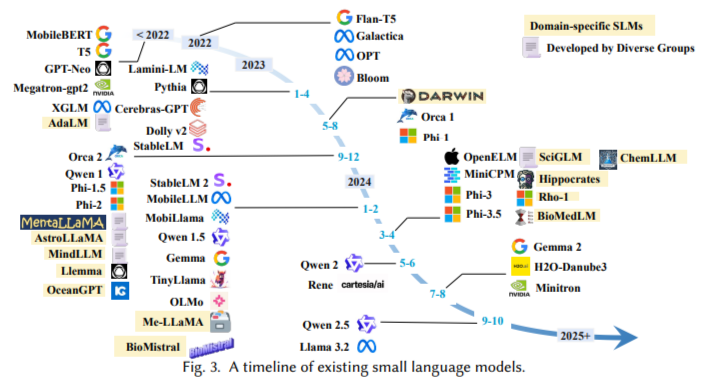
Researchers from Pennsylvania State University, University of Pennsylvania, UTHealth Houston, Amazon, and Rensselaer Polytechnic Institute have conducted a comprehensive survey on SLMs and looked into a systematic framework to develop SLMs that balance efficiency with LLM-like capabilities. This research aggregates advancements in fine-tuning, parameter sharing, and knowledge distillation to create models tailored for efficient and domain-specific use cases. Compact architectures and advanced data processing techniques enable SLMs to operate in low-power environments, making them accessible for real-time applications on edge devices. Institutional collaborations contributed to defining and categorizing SLMs, ensuring that the taxonomy supports deployment in low-memory, resource-limited settings.
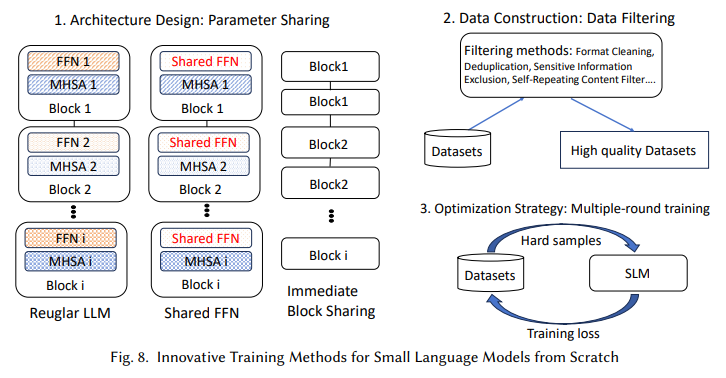
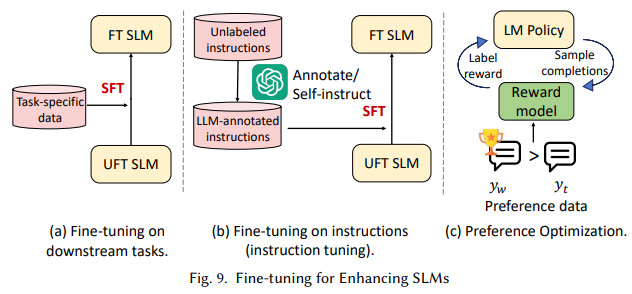
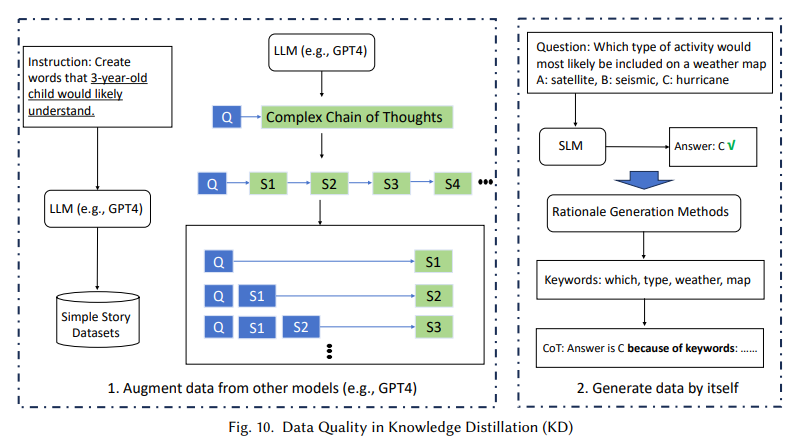
The technical methods proposed in this research are integral to optimizing SLM performance. For example, the survey highlights grouped query attention (GQA), multi-head latent attention (MLA), and Flash Attention as essential memory-efficient modifications that streamline attention mechanisms. These improvements allow SLMs to maintain high performance without requiring the extensive memory typical of LLMs. Also, parameter sharing and low-rank adaptation techniques ensure that SLMs can manage complex tasks in specialized fields like healthcare, finance, and customer support, where immediate response and data privacy are crucial. The framework’s emphasis on data quality further enhances model performance, incorporating filtering, deduplication, and optimized data structures to improve accuracy and speed in domain-specific contexts.
Empirical results underscore the performance potential of SLMs, as they can achieve efficiency close to that of LLMs in specific applications with reduced latency and memory use. In benchmarks across healthcare, finance, and personalized assistant applications, SLMs show substantial latency reductions and enhanced data privacy due to local processing. For example, latency improvements in healthcare and secure local data handling offer an efficient solution for on-device data processing and safeguarding sensitive patient information. The methods used in SLM training and optimization allow these models to retain up to 90% of LLM accuracy in domain-specific applications, a notable achievement given the reduction in model size and hardware requirements.
Key takeaways from the research:
- Computational Efficiency: SLMs operate with a fraction of the memory and processing power required by LLMs, making them suitable for devices with constrained hardware like smartphones and IoT devices.
- Domain-Specific Adaptability: With targeted optimizations such as fine-tuning and parameter sharing, SLMs retain approximately 90% of LLM performance in specialized domains, including healthcare and finance.
- Latency Reduction: Compared to LLMs, SLMs reduce response times by over 70%, providing real-time processing capabilities essential for edge applications and privacy-sensitive scenarios.
- Data Privacy and Security: SLM enables local processing, which reduces the need for data transfer to cloud servers and enhances privacy in high-stakes applications like healthcare and finance.
- Cost-Effectiveness: By lowering hardware and computational requirements, SLMs present a feasible solution for organizations with limited resources, democratizing access to AI-powered language models.

In conclusion, the survey on small language models presents a viable framework that addresses the critical issues of deploying LLMs in resource-constrained environments. The proposed SLM approach offers a promising path for integrating advanced language processing capabilities into low-power devices, extending the reach of AI technology across diverse fields. By optimizing latency, privacy, and computational efficiency, SLMs provide a scalable solution for real-world applications where traditional LLMs are impractical, ensuring language models’ broader applicability and sustainability in industry and research.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[AI Magazine/Report] Read Our Latest Report on ‘SMALL LANGUAGE MODELS‘
The post A Deep Dive into Small Language Models: Efficient Alternatives to Large Language Models for Real-Time Processing and Specialized Tasks appeared first on MarkTechPost.



