

Improving how large language models (LLMs) handle complex reasoning tasks while keeping computational costs low is a challenge. Generating multiple reasoning steps and selecting the best answer increases accuracy, but this process demands a lot of memory and computing power. Dealing with long reasoning chains or huge batches is computationally expensive and slows down models, rendering them inefficient under bounded computational resources. Other models of varying architectures have faster information processing and less memory, but their performance capability in reasoning tasks is unknown. Understanding whether these models can match or exceed existing ones under limited resources is important for making LLMs more efficient.
Currently, methods to improve reasoning in large language models rely on generating multiple reasoning steps and selecting the best answer using techniques like majority voting and trained reward models. The methods improve accuracy levels, although they need large computation systems, which makes them ill-suited for massive data processing. The processing power requirements and the memory needs of Transformer models slow down inference operations. Recurrent models and linear attention methods work faster in processing but lack effectiveness in reasoning operations. Knowledge distillation helps transfer knowledge from large to smaller models, but whether strong reasoning abilities transfer across different model types is unclear.
To mitigate these issues, researchers from University of Geneva, Together AI, Cornell University, EPFL, Carnegie Mellon University, Cartesia.ai, META and Princeton University proposed a distillation method to create subquadratic models with strong reasoning skills, improving efficiency while preserving reasoning capabilities. The distilled models outperformed their Transformer teachers on MATH and GSM8K tasks, achieving similar accuracy with 2.5× lower inference time. This demonstrated that reasoning and mathematical skills could transfer across architectures while reducing computational costs.
The framework included two model types: pure Mamba models (Llamba) and hybrid models (MambaInLlama). Llamba used the MOHAWK distillation method, aligning matrices, matching hidden states, and transferring weights while training on an 8B-token dataset. MambaInLlama retained Transformer attention layers but replaced others with Mamba layers, using reverse KL divergence for distillation. Experiments demonstrated dataset choice had a large effect on performance, with certain datasets lowering Llamba-1B accuracy by 10% and showing a poor correlation between general benchmarks and mathematical reasoning, emphasizing the importance of improved training data.
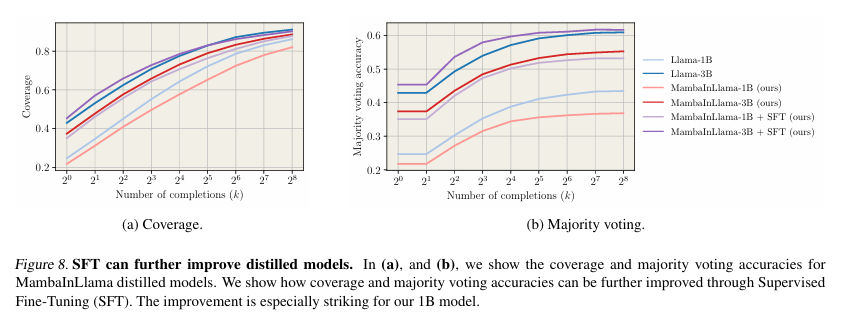
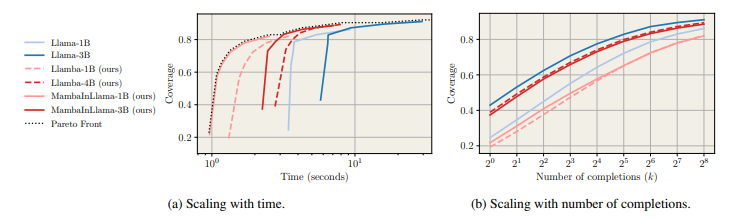
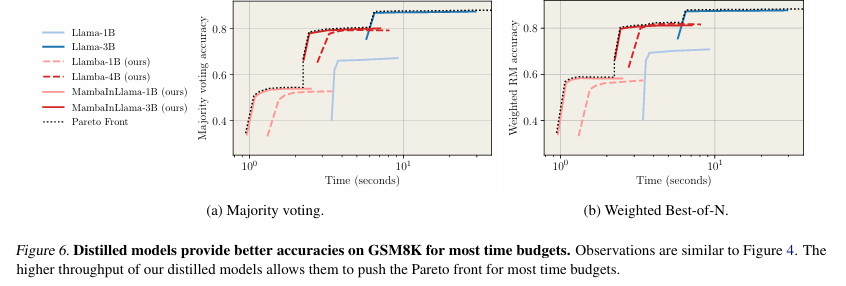
Researchers evaluated distilled models for generating multiple chains of thought (CoTs) in math problem-solving, focusing on instruction-following retention. They measured coverage using pass@k, estimated the probability of finding a correct solution among k samples, and assessed accuracy through majority voting and Best-of-N selection with a Llama-3.1 8B-based reward model. Benchmarks showed distilled models performed up to 4.2× faster than Llama models while maintaining comparable coverage, generating more completions within fixed compute budgets, and outperforming smaller transformer baselines in speed and accuracy. Furthermore, supervised fine-tuning (SFT) after distillation enhanced performance, validating their effectiveness in structured reasoning tasks such as coding and formal proofs.
In summary, the proposed Distilled Mamba models enhanced reasoning efficiency by retaining accuracy while cutting inference time and memory consumption. When computational budgets were fixed, the models outperformed Transformers; hence, they are suitable for scalable inference. This method can serve as a basis for future research in training good reasoning models, improving distillation methods, and building reward models. Inference scaling advancements would further enhance their application in AI systems that demand faster and more effective reasoning.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.

The post Accelerating AI: How Distilled Reasoners Scale Inference Compute for Faster, Smarter LLMs appeared first on MarkTechPost.