

Reward modeling is critical in aligning LLMs with human preferences, particularly within the reinforcement learning from human feedback (RLHF) framework. Traditional reward models (RMs) assign scalar scores to evaluate how well LLM outputs align with human judgments, guiding optimization during training to improve response quality. However, these models often need more interpretability, are prone to robustness issues like reward hacking, and fail to leverage LLMs’ language modeling capabilities fully. A promising alternative is the LLM-as-a-judge paradigm, which generates critiques alongside scalar scores to enhance interpretability. Recent research has sought to combine the strengths of traditional RMs and the LLM-as-a-judge approach by generating both critiques and scalar rewards, providing richer feedback signals. However, integrating critiques into RMs is challenging due to conflicting objectives between language generation and reward optimization and the resource-intensive nature of training fine-tuned evaluators.
Recent advancements in reward modeling aim to overcome these challenges through innovative methods. Some studies incorporate critiques from teacher LLMs without additional RM training, while others train reward models to generate critiques and scores using knowledge distillation jointly. While these approaches demonstrate potential, they often depend on costly, high-quality critiques generated by teacher models, limiting their scalability. Furthermore, they need help with subjective tasks where ground-truth answers are unavailable. Self-alignment techniques, which leverage the LLM’s capabilities to generate critiques and preference labels, offer a cost-effective alternative to human annotations. By combining self-generated critiques with human-annotated data, researchers aim to enhance the robustness and efficiency of reward models, aligning them more effectively with human preferences across diverse domains.
Critic-RM, developed by researchers from GenAI, Meta, and Georgia Institute of Technology, enhances reward models through self-generated critiques, eliminating the need for strong LLM teachers. It employs a two-stage process: generating critiques with discrete scores and filtering them using consistency-based methods aligned with human preferences. A weighted training strategy balances critique modeling and reward prediction, ensuring accuracy and robustness. Critic-RM improves reward modeling accuracy by 3.7%–7.3% on benchmarks like RewardBench and CrossEval and enhances reasoning accuracy by 2.5%–3.2%. This framework demonstrates strong performance across diverse tasks, leveraging high-quality critiques to refine predictions and correct flawed reasoning.
The Critic-RM framework enhances reward model training by incorporating critiques as intermediate variables between responses and final rewards. It involves critique generation using an instruction-finetuned LLM, followed by filtering and refinement to ensure high-quality critiques aligned with human preferences. The reward model is trained on preference modeling and critique generation objectives, with a dynamic weighting scheme to balance both during training. During inference, the model generates critiques and predicts rewards based on responses augmented with these critiques. Inference-time scaling improves performance by averaging rewards over multiple generated critiques with non-zero temperatures.
The study utilizes public and synthetic datasets to train reward models with preference pairs. Public datasets include ChatArena, AlpacaFarm-HumanPref, HelpSteer2, Evol-instruct, and PKU-SafeRLHF, covering domains like general chat, helpfulness, reasoning, and safety. Synthetic datasets are generated using Llama-3.1 models, with correct and incorrect responses identified for math tasks (GSM8K, MATH) and safety scenarios based on SafeRLHF guidelines. Evaluation benchmarks include RewardBench, CrossEval, QA Feedback, SHP, and CriticBench, assessing performance on preference accuracy, critique quality, and correction ability. Critic-RM outperforms baselines, highlighting the importance of high-quality critiques for improved reward modeling, especially in complex tasks.
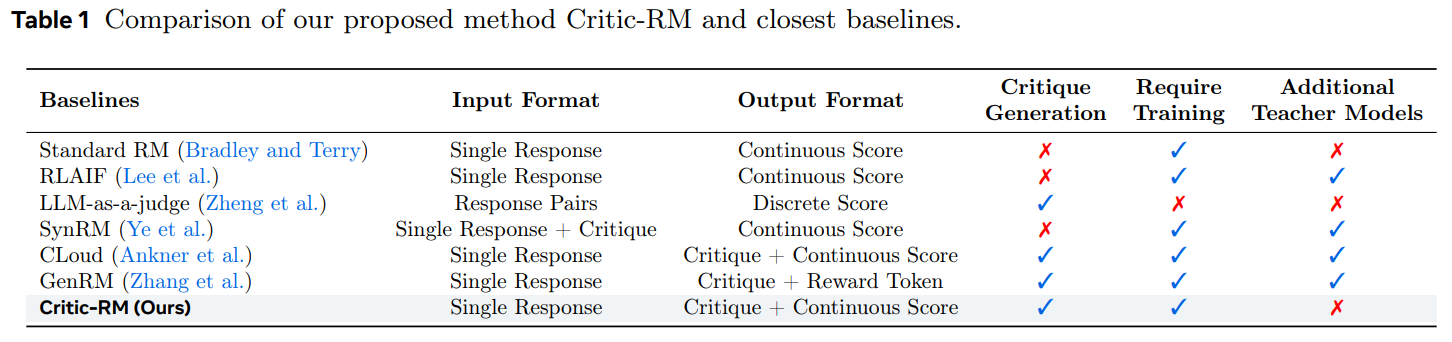
In conclusion, Critic-RM introduces a self-critiquing framework to improve reward modeling for LLMs. It generates both critiques and scalar rewards, enhancing preference ranking by incorporating explicit rationales as evidence. The framework uses a two-step process: first, it generates and filters high-quality critiques, and then it jointly fine-tunes reward prediction and critique generation. Experimental results on benchmarks like RewardBench and CrossEval show that Critic-RM achieves 3.7%-7.3% higher accuracy than standard models, with strong data efficiency. Additionally, the generated critiques improve reasoning accuracy by 2.5%-3.2%, demonstrating the framework’s effectiveness in refining flawed reasoning and aligning LLMs with human preferences.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 60k+ ML SubReddit.
 [Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
[Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
The post Critic-RM: A Self-Critiquing AI Framework for Enhanced Reward Modeling and Human Preference Alignment in LLMs appeared first on MarkTechPost.



