

Machine learning is advancing rapidly, particularly in areas requiring extensive data processing, such as natural language understanding and generative AI. Researchers are constantly striving to design algorithms that maximize computational efficiency while improving the accuracy and performance of large-scale models. These efforts are critical for building systems capable of managing the complexities of language representation, where precision and resource optimization are key.
One persistent challenge in this field is balancing computational efficiency with model accuracy, especially as neural networks scale to handle increasingly complex tasks. Sparse Mixture-of-Experts (SMoE) architectures have shown promise by using dynamic parameter selection to improve performance. However, these models often need help processing multi-representation spaces effectively, limiting their ability to exploit available data fully. This inefficiency has created a demand for more innovative methods to leverage diverse representation spaces without compromising computational resources.
SMoE architectures traditionally use gating mechanisms to route tokens to specific experts, optimizing the use of computational resources. These models have succeeded in various applications, particularly through top-1 and top-2 gating methods. However, while these methods excel at parameter efficiency, they cannot harness the full potential of multi-representational data. Furthermore, the standard approach of embedding sparse layers within a Transformer framework limits their capacity to scale effectively while maintaining operational efficiency.
Researchers from Microsoft have presented a novel implementation of the MH-MoE framework. This design builds on the foundations of SMoE while addressing its limitations. The MH-MoE implementation allows for the efficient processing of diverse representation spaces by introducing a multi-head mechanism and integrating projection layers. This approach ensures that the computational and parameter efficiency of traditional SMoE models is preserved while significantly enhancing their representational capacity.
The methodology behind MH-MoE is centered on enhancing the information flow through a refined multi-head mechanism. Input tokens are split into sub-tokens, routed to distinct heads, and then processed in parallel. This process is facilitated by linear projection layers that transform the tokens before and after passing through the mixture-of-experts layer. By adjusting the intermediate dimensions and optimizing the gating mechanism, the model ensures FLOPs parity with traditional SMoE models. In one configuration, the researchers used two heads with an intermediate dimension of 768 and top-2 gating, increasing the number of experts to 40. Another configuration employed three heads with an intermediate dimension of 512, utilizing top-3 gating and 96 experts. These adjustments illustrate the adaptability of MH-MoE in aligning its computational efficiency with performance goals.
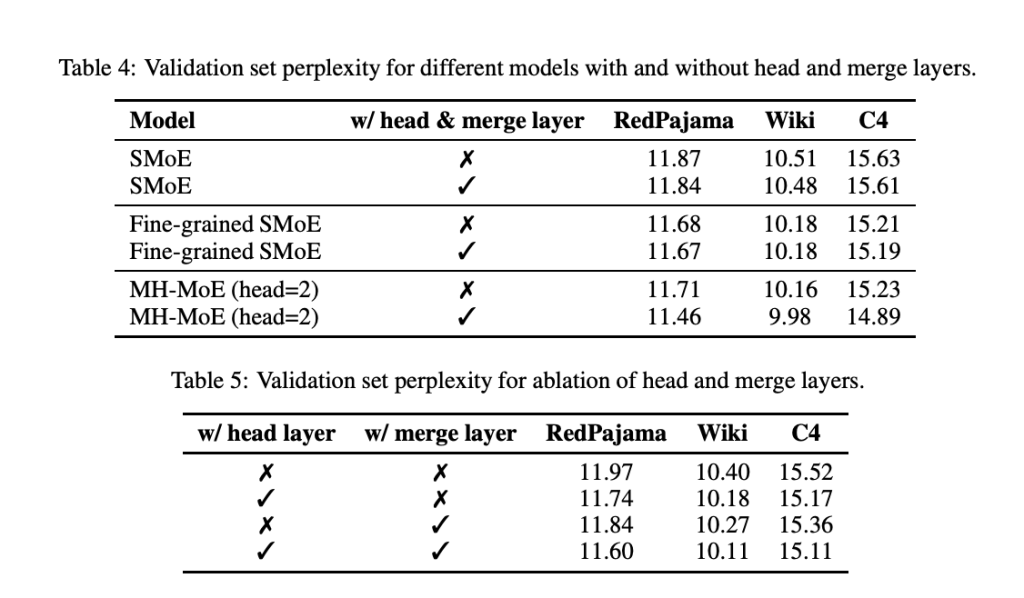
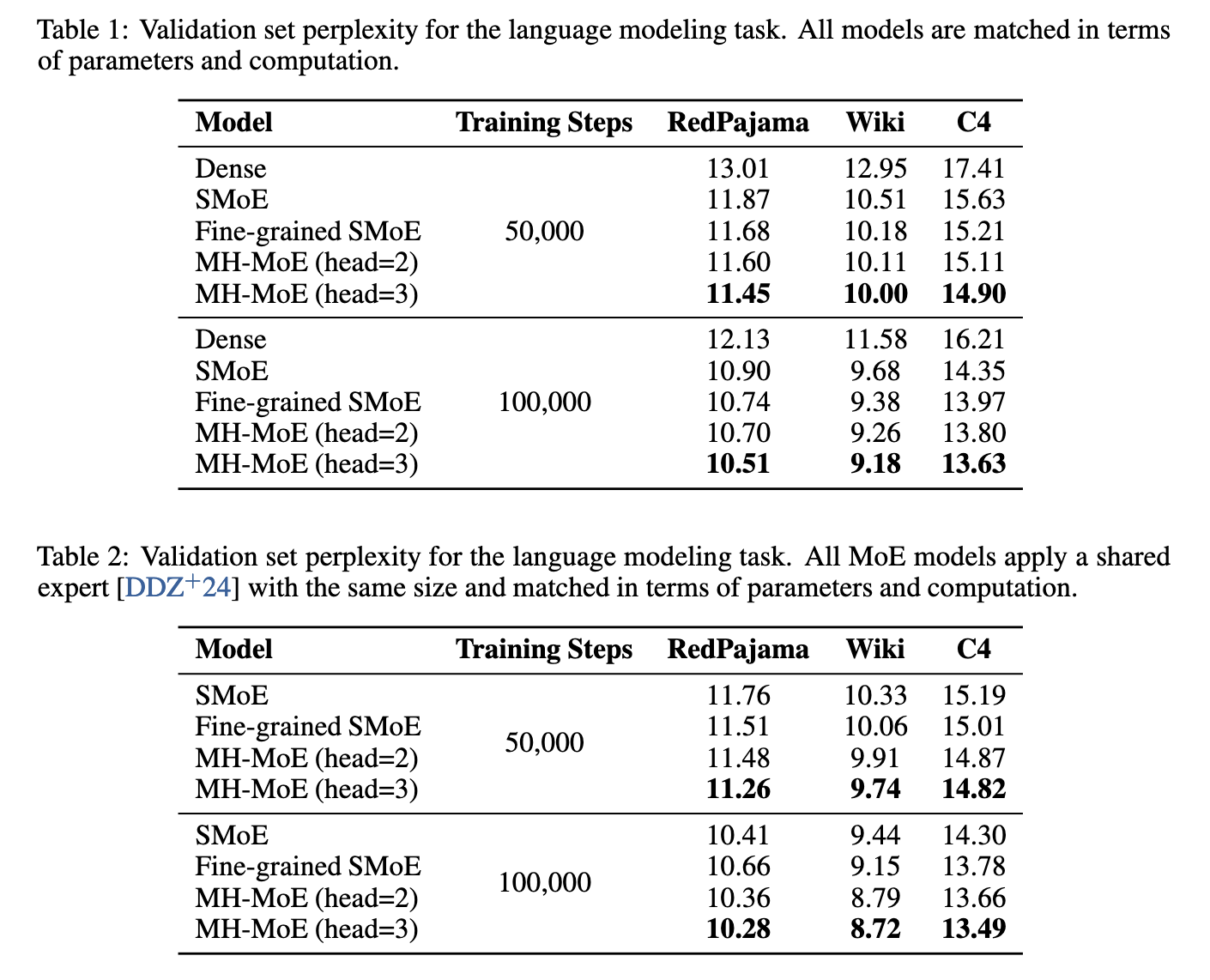
Experiments demonstrated that MH-MoE consistently outperformed existing SMoE models across various benchmarks. In language modeling tasks, the model achieved significant improvements in perplexity, a measure of model accuracy. For example, after 100,000 training steps, the three-head MH-MoE achieved a perplexity of 10.51 on the RedPajama dataset compared to 10.74 for fine-grained SMoE and 10.90 for standard SMoE. On the Wiki dataset, the three-head MH-MoE achieved a perplexity of 9.18, further underscoring its superior performance. Further, in experiments involving 1-bit quantization using BitNet, MH-MoE maintained its performance advantage, achieving a perplexity of 26.47 after 100,000 steps on the RedPajama dataset compared to 26.68 for fine-grained SMoE and 26.78 for standard SMoE.
Ablation studies conducted by the research team highlighted the importance of the head and merge layers in MH-MoE’s design. These studies demonstrated that both components contribute significantly to model performance, with the head layer offering a more substantial improvement than the merge layer. For example, adding the head layer reduced perplexity on the RedPajama dataset from 11.97 to 11.74. These findings emphasize the critical role of these layers in enhancing the model’s ability to integrate and utilize multi-representational data.
The researchers’ efforts have resulted in a model that addresses key limitations of traditional SMoE frameworks while setting a new benchmark for performance and efficiency. MH-MoE offers a robust solution for effectively scaling neural networks by leveraging multi-head mechanisms and optimizing computational design. This innovation marks a significant step in developing efficient and powerful machine-learning models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.

 ‘
‘The post Microsoft Researchers Present a Novel Implementation of MH-MoE: Achieving FLOPs and Parameter Parity with Sparse Mixture-of-Experts Models appeared first on MarkTechPost.