

Model efficiency is important in the age of large language and vision models, but they face significant efficiency challenges in real-world deployments. Critical metrics such as training compute requirements, inference latency, and memory footprint impact deployment costs and system responsiveness. These constraints often limit the practical implementation of high-quality models in production environments. The need for efficient deep learning methods has become important, focusing on optimizing the trade-off between model quality and resource footprint. While various approaches including algorithmic techniques, efficient hardware solutions, and best practices have emerged, architectural improvements remain fundamental to efficiency gains.
Several approaches have emerged to address model efficiency challenges, each with distinct focuses and limitations. Existing methods like LoRA introduce low-rank adapter weights during fine-tuning while keeping other weights constant, and AltUp creates parallel lightweight transformer blocks to simulate larger model dimensions. Other methods like compression techniques, include quantization and pruning to reduce model size and latency but can impact model quality. Knowledge distillation techniques transfer knowledge from larger teacher models to smaller student models, and progressive learning approaches like Stacking and RaPTr grow networks gradually. However, these methods involve complex training or trade-offs between efficiency and performance.
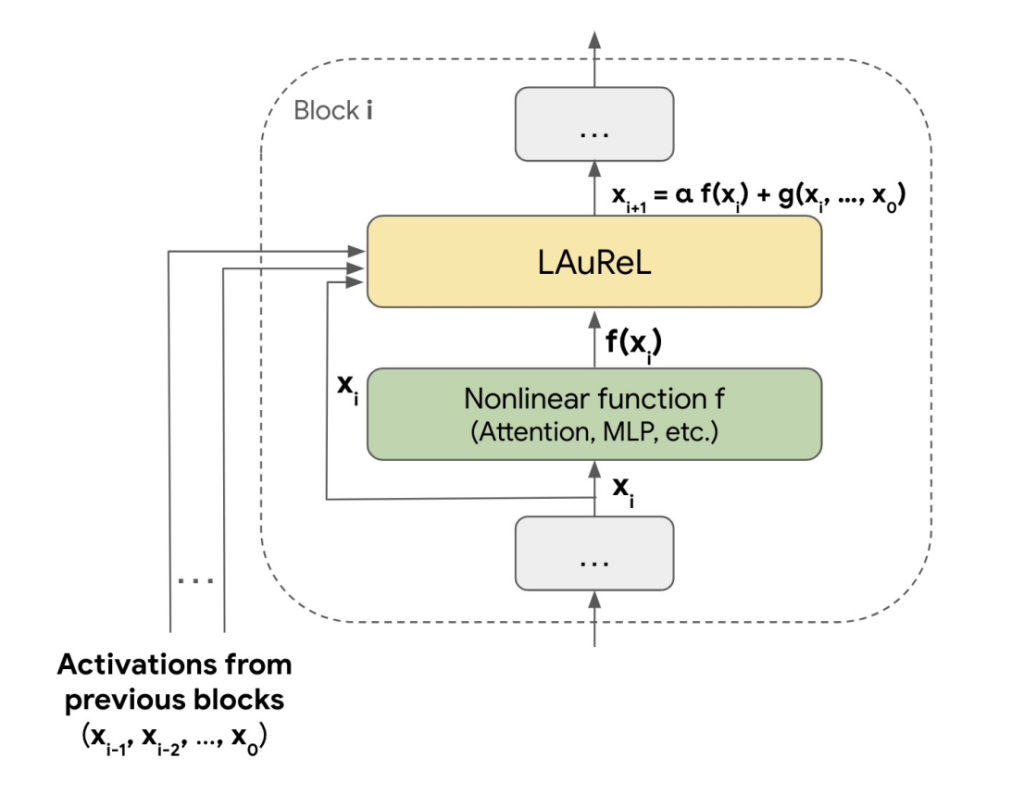
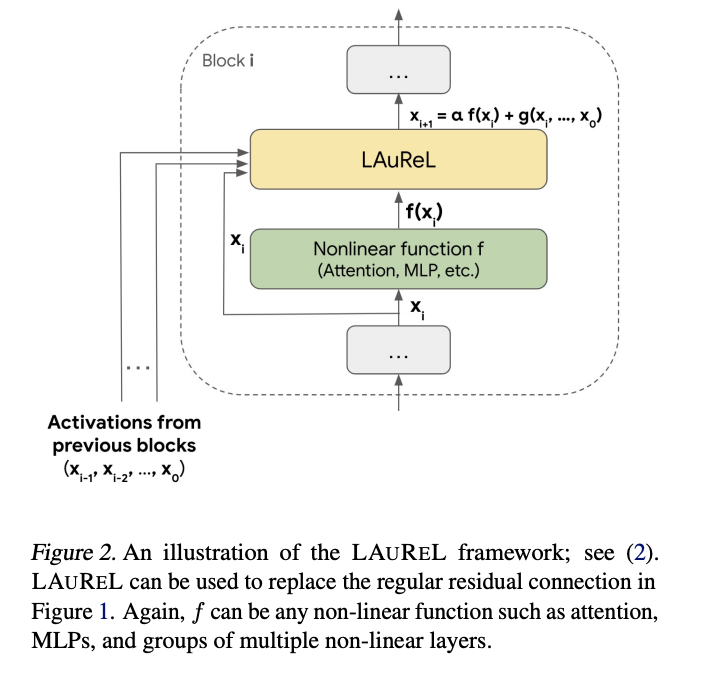
Researchers from Google Research, Mountain View, CA, and Google Research, New York, NY have proposed a novel method called Learned Augmented Residual Layer (LAUREL), which revolutionizes the traditional residual connection concept in neural networks. It serves as a direct replacement for conventional residual connections while improving both model quality and efficiency metrics. LAUREL shows remarkable versatility, with significant improvements across vision and language models. When implemented in ResNet-50 for ImageNet 1K classification, LAUREL achieves 60% of the performance gains associated with adding an entire extra layer, with only 0.003% additional parameters. This efficiency translates to matching full-layer performance with 2.6 times fewer parameters.
LAUREL’s implementation is tested in both vision and language domains, focusing on the ResNet-50 model for ImageNet-1K classification and a 3B parameter decoder-only transformer for language tasks. The architecture seamlessly integrates with existing residual connections, requiring minimal modifications to standard model architectures. For vision tasks, the implementation involves incorporating LAUREL into ResNet-50’s skip connections and training on ImageNet 1K using 16 Cloud TPUv5e chips with data augmentation. In the language domain, two variants of LAUREL (LAUREL-RW and LAUREL-LR) are implemented in a 3B parameter transformer model and trained from scratch on text tokens using 1024 Cloud TPU v5e chips over two weeks.
The results demonstrate LAUREL’s superior efficiency compared to traditional scaling methods. In vision tasks, adding an extra layer to ResNet-50 enhances accuracy by 0.25% with 4.37% more parameters, but LAUREL-RW achieves 0.15% improvement with just 0.003% parameter increase. The LAUREL-RW+LR variant matches the performance of the extra-layer approach while using 2.6 times fewer parameters, and LAUREL-RW+LR+PA outperforms it with 1.82 times fewer parameters. Moreover, in language models, LAUREL shows consistent improvements across tasks including Q&A, NLU, Math, and Code with only a 0.012% parameter increase. This minimal parameter addition makes LAUREL efficient for large-scale models.
In conclusion, researchers introduced the LAUREL framework which represents a significant advancement in neural network architecture, offering a complex alternative to traditional residual connections. Its three variants – LAUREL-RW, LAUREL-LR, and LAUREL-PA – can be flexibly combined to optimize performance across different applications. The framework’s success in both vision and language tasks, along with its minimal parameter overhead shows its potential as a superior alternative to conventional model scaling approaches. The versatility and efficiency of LAUREL make it a promising candidate for future applications in other architectures like Vision Transformers (ViT).
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Intelligent Document Processing with GenAI in Financial Services and Real Estate Transactions– From Framework to Production
The post Google AI Introduces LAuReL (Learned Augmented Residual Layer): Revolutionizing Neural Networks with Enhanced Residual Connections for Efficient Model Performance appeared first on MarkTechPost.