

Knowledge bases like Wikidata, Yago, and DBpedia have served as fundamental resources for intelligent applications, but innovation in general-world knowledge base construction has been stagnant over the past decade. While Large Language Models (LLMs) have revolutionized various AI domains and shown potential as sources of structured knowledge, extracting and materializing their complete knowledge remains a significant challenge. Current approaches mainly focus on sample-based evaluations using question-answering datasets or specific domains, falling short of comprehensive knowledge extraction. Moreover, scaling the methods of knowledge bases from LLMs through factual prompts and iterative graphs effectively while maintaining accuracy and completeness poses technical and methodological challenges.
Existing knowledge base construction methods follow two main paradigms: volunteer-driven approaches like Wikidata and structured information harvesting from sources like Wikipedia, exemplified by Yago and DBpedia. Text-based knowledge extraction systems like NELL and ReVerb represent an alternative approach but have seen limited adoption. Current methods for evaluating LLM knowledge primarily depend on sampling specific domains or benchmarks, failing to capture their knowledge’s full extent. While some attempts have been made to extract knowledge from LLMs through prompting and iterative exploration, these efforts have been limited in scale or focused on specific domains.
Researchers from ScaDS.AI & TU Dresden, Germany, and Max Planck Institute for Informatics, Saarbrücken, Germany have proposed an approach to construct a large-scale knowledge base entirely from LLMs. They introduced GPTKB, built using GPT-4o-mini, demonstrating the feasibility of extracting structured knowledge at scale while addressing specific challenges in entity recognition, canonicalization, and taxonomy construction. The resulting knowledge base contains 105 million triples covering more than 2.9 million entities, achieved at a fraction of the cost compared to traditional KB construction methods. This approach bridges two domains: it provides insights into LLMs’ knowledge representation and advances general-domain knowledge base construction methods.
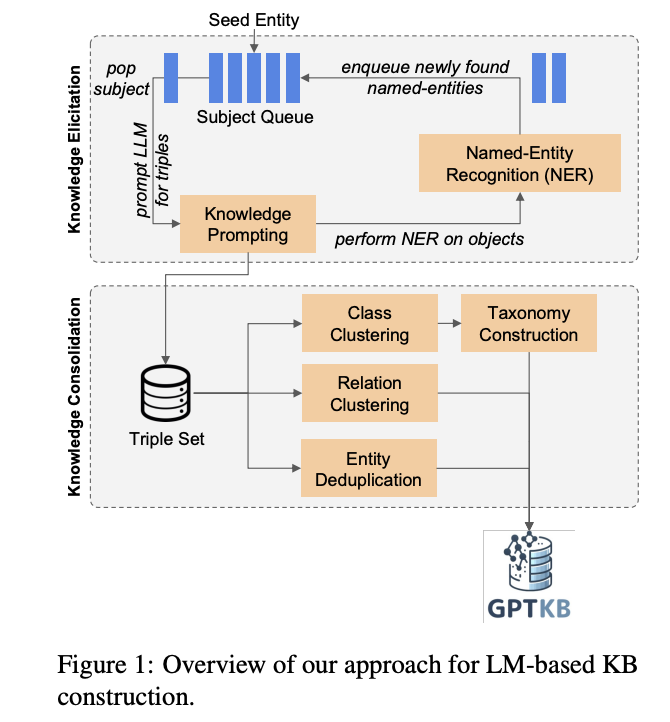
The architecture of GPTKB follows a two-phase approach to knowledge extraction and organization. The first phase implements an iterative graph expansion process, starting from a seed subject (Vannevar Bush) and systematically extracting triples while identifying newly named entities for further exploration. This expansion process uses a multi-lingual named entity recognition (NER) system using spaCy models across 10 major languages, with rule-based filters to maintain focus on relevant entities and prevent drift into linguistic or translation-related content. The second phase emphasizes consolidation, which includes entity canonicalization, relation standardization, and taxonomy construction. This system operates independently of existing knowledge bases or standardized vocabularies, depending only on the LLM’s knowledge.
GPTKB shows significant scale and diversity in its knowledge representation, containing patent and person-related information, with nearly 600,000 human entities. The most common properties are patentCitation (3.15 M) and instanceOf (2.96 M), with person-specific properties like “hasOccupation” (126K), “knownFor” (119K), and nationality (114K). Comparative analysis with Wikidata reveals that only 24% of GPTKB subjects have exact matches in Wikidata, with 69.5% being potentially novel entities. The knowledge base also captures properties not modeled in Wikidata, such as “historicalSignificance” (270K triples), hobbies (30K triples), and “hasArtStyle” (11K triples), suggesting significant novel knowledge contribution.

In conclusion, researchers introduced an approach to construct a large-scale knowledge base entirely from LLMs. They provided successful development of GPTKB which shows the feasibility of constructing large-scale knowledge bases directly from LLMs, marking a significant advancement in natural language processing and semantic web domains. While challenges remain in ensuring precision and handling tasks like entity recognition and canonicalization, the approach has proven highly cost-effective, generating 105 million assertions for over 2.9 million entities at a fraction of traditional costs. This approach provides valuable insights into LLMs’ knowledge representation and opens a new door for open-domain knowledge base construction on how structured knowledge is extracted and organized from language models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[AI Magazine/Report] Read Our Latest Report on ‘SMALL LANGUAGE MODELS‘
The post GPTKB: Large-Scale Knowledge Base Construction from Large Language Models appeared first on MarkTechPost.