

In recent years, Automatic Speech Recognition (ASR) technology has gained significant traction, transforming industries ranging from healthcare to customer support. However, achieving accurate transcription across diverse languages, accents, and noisy environments remains challenging. Current speech-to-text models often face issues like inaccuracies in understanding complex accents, handling domain-specific terminology, and dealing with background noise. The need for a more robust, adaptable, and scalable speech-to-text solution is evident, especially as the demand for such technology rises with the proliferation of AI-driven applications in day-to-day life.
Assembly AI Introduces Universal-2: A New Speech-to-Text Model with Major Improvements
In response to these challenges, Assembly AI has introduced Universal-2, a new speech-to-text model designed to offer significant improvements over its predecessor, Universal-1. This upgraded model aims to enhance transcription accuracy across a broader spectrum of languages, accents, and scenarios. Assembly AI’s Universal-2 leverages cutting-edge advancements in deep learning and speech processing, enabling a more nuanced understanding of human speech even in challenging conditions like poor audio quality or heavy background noise. According to Assembly AI, the release of Universal-2 is a milestone in their journey toward creating the most comprehensive and accurate ASR solution in the industry.
The Universal-2 model has been built on top of the previous version with substantial refinements in architecture and training methodologies. It introduces enhanced multilingual support, making it a truly versatile ASR solution capable of delivering high-quality results across various languages and dialects. One of the key differentiators of Universal-2 is its ability to maintain consistent performance even in low-resource settings, meaning that the model doesn’t falter when transcribing under less-than-ideal conditions. This makes it ideal for applications like call centers, podcasts, and multilingual meetings where speech quality can vary significantly. Additionally, Universal-2 is designed with scalability in mind, offering developers an easy integration experience with a wide array of APIs for rapid deployment.
Technical Details and Benefits of Universal-2

Universal-2 is based on an ASR decoder architecture called the Recurrent Neural Network Transducer (RNN-T). Compared to Universal-1, the model employs a broader training dataset, encompassing diverse speech patterns, multiple dialects, and varying audio qualities. This broader dataset helps the model learn to be more adaptive and precise, reducing the word error rate (WER) compared to its predecessor.
Moreover, the improvements in noise robustness allow Universal-2 to handle real-world audio scenarios more effectively. It has also been optimized for faster processing speeds, enabling near real-time transcription—a crucial feature for applications in sectors like customer service, live broadcasting, and automated meeting transcription. These technical enhancements help bridge the gap between human-level understanding and machine-level transcription, which has long been a target for AI researchers and developers.
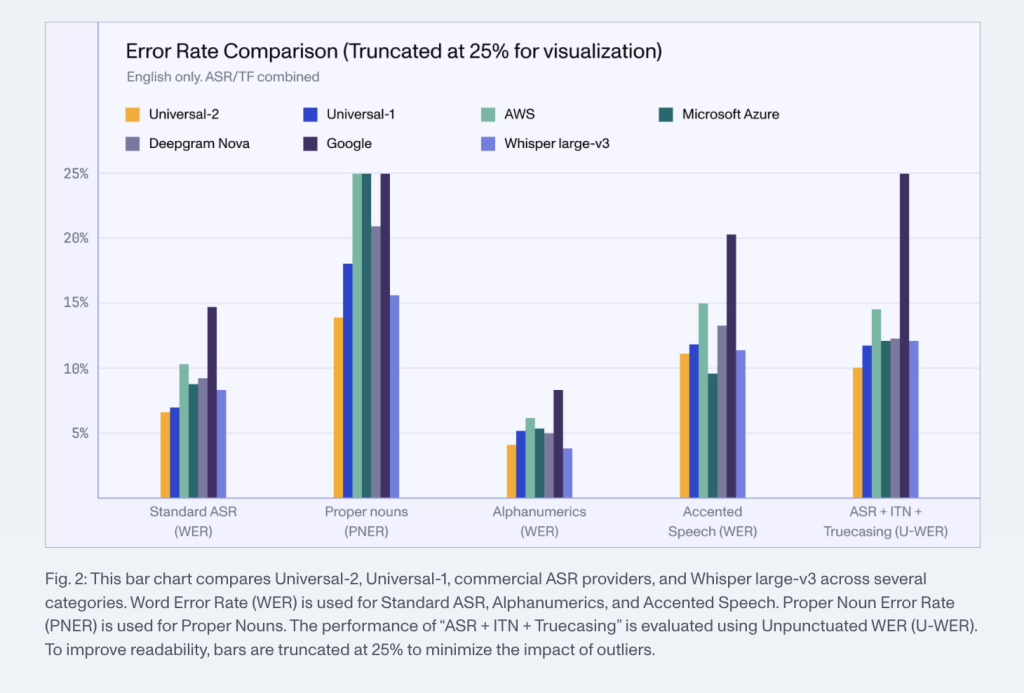
The Importance of Universal-2 and Its Performance Metrics
The introduction of Universal-2 is a significant step forward for the ASR industry. Enhanced accuracy and robustness mean that businesses can rely on transcription services with increased confidence, even when dealing with complex audio environments. Assembly AI has reported a notable decrease in the word error rate of Universal-2—a 32% reduction compared to Universal-1. This improvement translates into fewer transcription errors, better customer experiences, and higher efficiency for tasks such as subtitling videos, generating meeting notes, or powering voice-controlled applications.

Another critical aspect is Universal-2’s enhanced performance across different languages and accents. In an increasingly interconnected world, the ability to accurately transcribe non-English languages or handle strong regional accents opens up new opportunities for businesses and services. This broader applicability makes Universal-2 highly valuable in regions where language diversity poses a challenge to conventional ASR systems. By pushing the envelope on multilingual support, Assembly AI continues to make strides in democratizing access to cutting-edge AI technologies.
Conclusion
With Universal-2, Assembly AI is setting a new standard in the speech-to-text landscape. The model’s enhanced accuracy, speed, and adaptability make it a robust choice for developers and businesses looking to leverage the latest in ASR technology. By addressing previous challenges, such as the need for better noise handling and multilingual support, Universal-2 not only builds upon the strengths of its predecessor but also introduces new capabilities that make speech recognition more accessible and effective for a wider range of applications. As industries continue to integrate AI-driven tools into their workflows, advancements like Universal-2 bring us closer to seamless human-computer communication, laying the groundwork for more intuitive and efficient interactions.
Check out the Details. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[AI Magazine/Report] Read Our Latest Report on ‘SMALL LANGUAGE MODELS‘
The post Assembly AI Introduces Universal-2: The Next Leap in Speech-to-Text Technology appeared first on MarkTechPost.