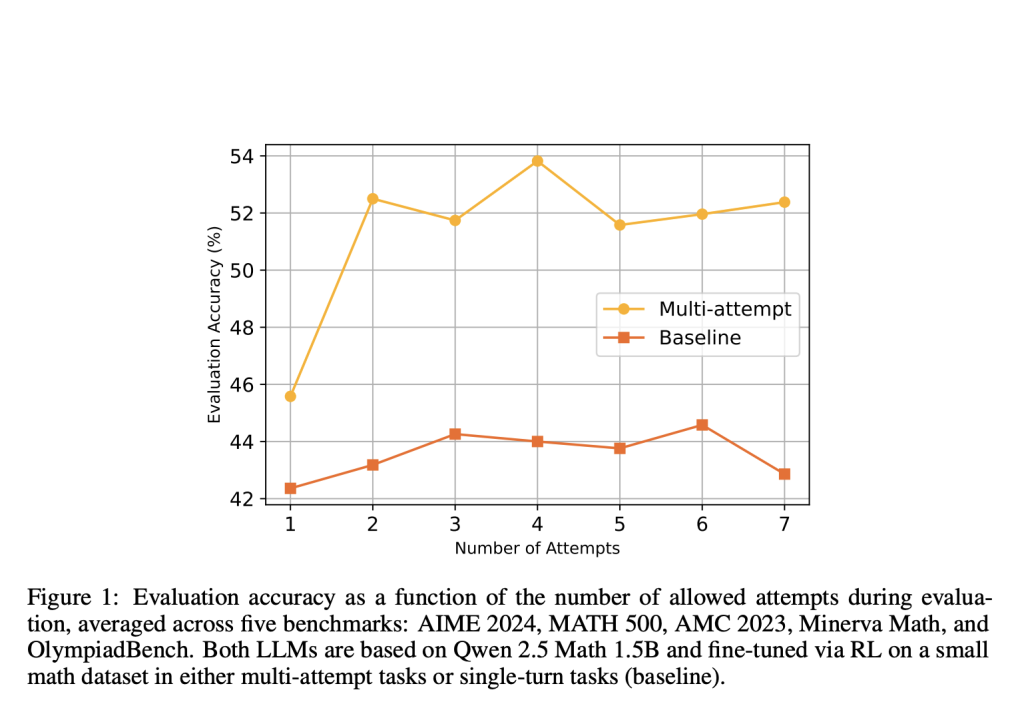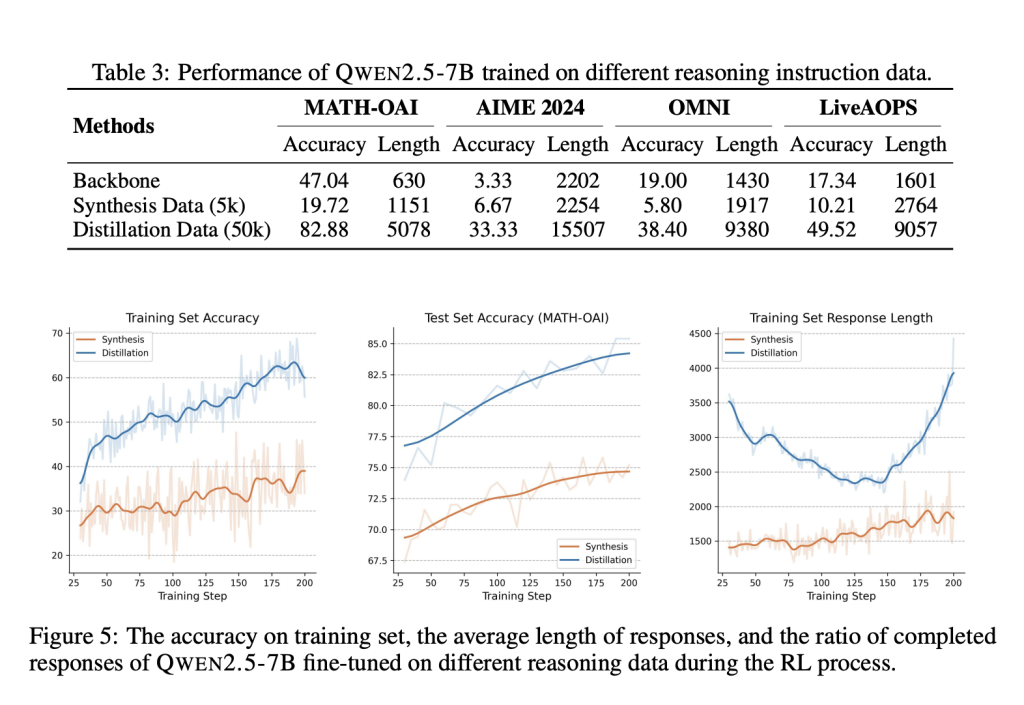
This AI Paper Introduces RL-Enhanced QWEN 2.5-32B: A Reinforcement Learning Framework for Structured LLM Reasoning and Tool Manipulation
Large reasoning models (LRMs) employ a deliberate, step-by-step thought process before arriving at a solution, making them suitable for complex