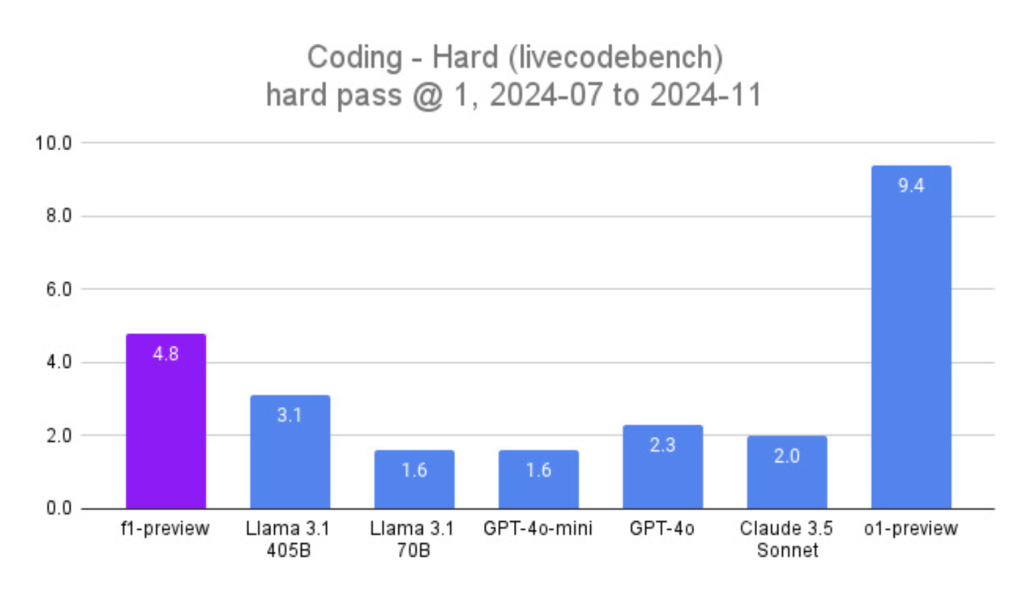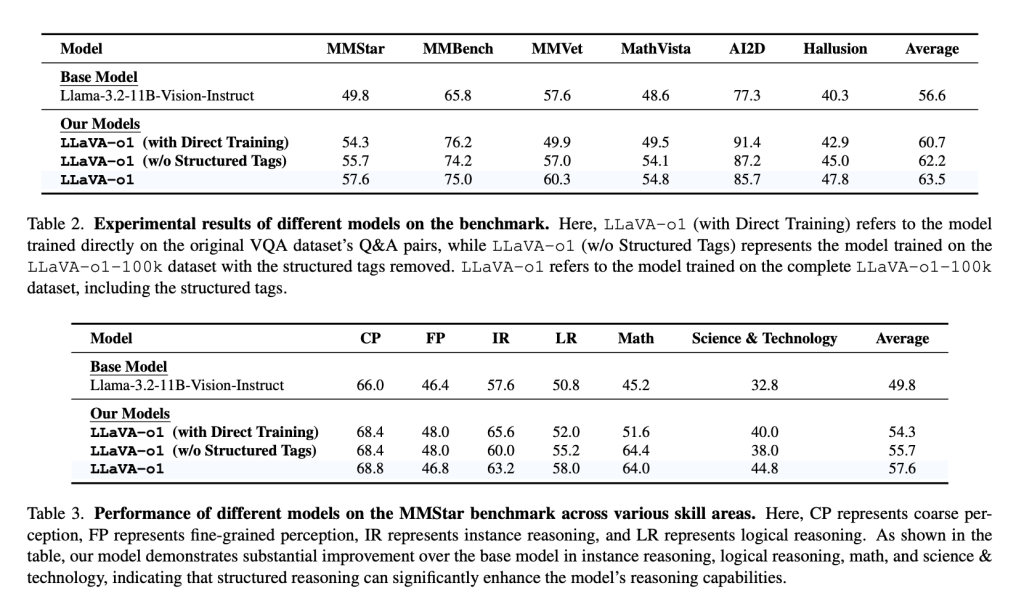
Meet LLaVA-o1: The First Visual Language Model Capable of Spontaneous, Systematic Reasoning Similar to GPT-o1
The development of vision-language models (VLMs) has faced challenges in handling complex visual question-answering tasks. Despite substantial advances in reasoning